EDA 入門:從 RTL 到矽晶片(中譯)
May 26, 2026 · 閱讀時間約 65 分鐘
 Kai-Yin Hung
Kai-Yin Hung 從暫存器傳輸層描述到實體矽晶片,帶你走完晶片設計的完整旅程,並認識電子設計自動化工具如何撐起現代半導體產業。
原文:The EDA Primer: From RTL to Silicon by semianalysis(2026)
EDA 入門:從 RTL 到矽晶片
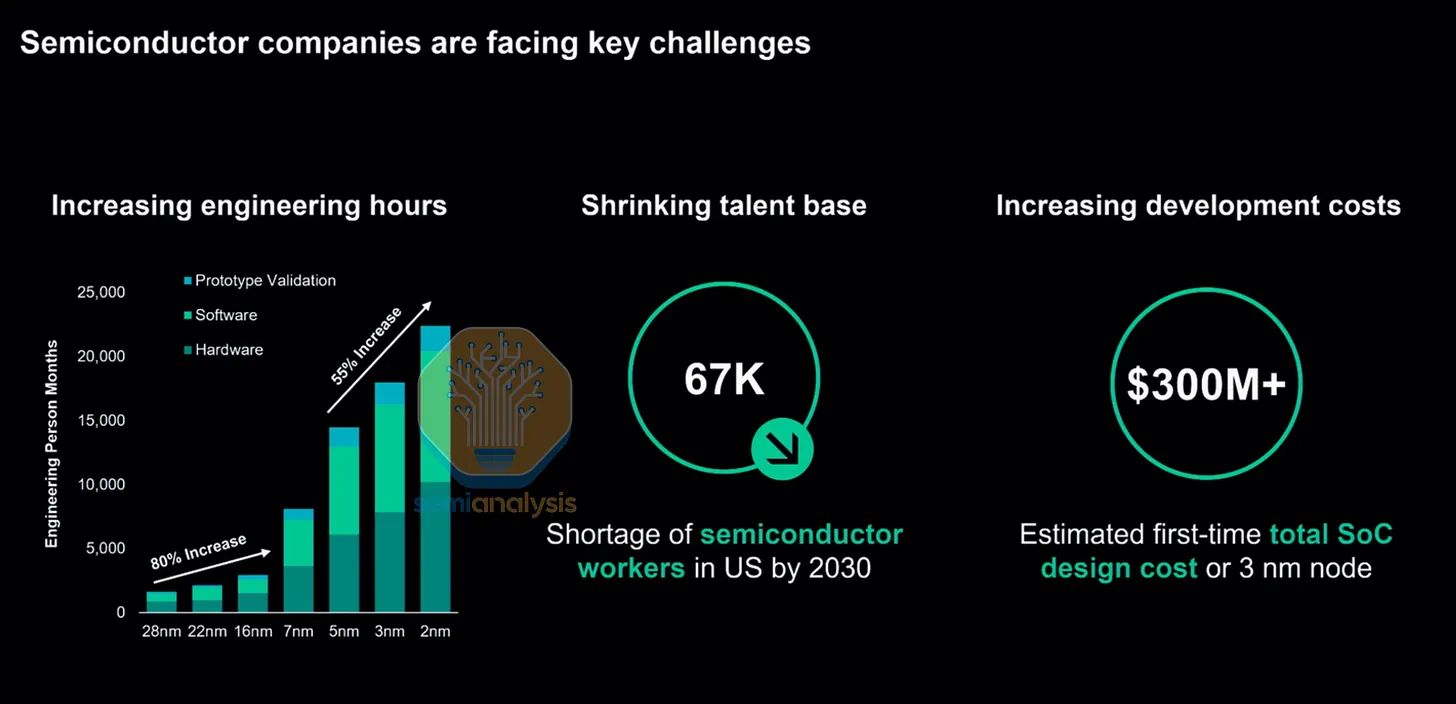
AI 對算力的需求,推動了過去幾年的爆炸性成長。晶片設計隨之愈趨複雜,每代產品的矽晶片面積與單封裝功耗持續攀升,以追求更高的效能。每一個新世代,新製程節點帶來更多設計規則與限制,進一步推高晶片設計成本。
與此同時,市場急於搶先推出算力產品,設計團隊承受巨大壓力,必須壓縮時程、加速驗證週期,從以年計算縮短至以月計算。慢了就會被對手甩開。哪怕只晚了三個月,就可能意味著數十億美元的損失。
來源:Siemens
與此同時,工程人才的儲備正在萎縮。豐厚薪酬與彈性工作模式吸引了大批學生投入軟體與資訊系統領域,導致願意投入晶片設計行業的電機工程畢業生愈來愈少。Siemens 指出,眾多複雜 AI 加速器設計所需的工程人時,已遠遠超出現有人才流入速度。
美國半導體從業人員中,有三分之一年齡超過 55 歲,而新畢業生的補充速度根本跟不上這道缺口。就連 Apple 也在積極資助教育計畫,試圖吸引更多學生踏入工程領域。儘管他們的「New Silicon Initiative」確實提升了電機工程畢業生的數量,但與電晶體數量以摩爾定律速度增長所帶動的人力需求相比,這點改善幾乎微不足道。
![]()
來源:Apple
晶片複雜度上升、設計時程壓縮、工程師短缺,三重困境疊加,在設計階段形成了嚴重瓶頸。最新的 AMD MI455X 在 2 奈米與 3 奈米製程上,以先進的混合鍵合 3D 晶粒堆疊技術,將 3,200 億顆電晶體分布於 12 顆邏輯晶粒上,並整合 HBM4 記憶體與 224G SerDes 高速介面。設計這種規模的晶片,不是多雇幾個工程師或多買幾台驗證伺服器就能解決的問題——它考驗的是一家公司的工具鏈、方法論與人才組織架構,決定著設計成敗。
花了數億美元設計一顆新 SoC,並不能保證晶片一定能正常運作。通常需要多次流片改版才能到位,A0 版本鮮少直接進入量產。一套先進光罩動輒數千萬美元,每次改版都是對財務的一記重擊,同時也讓高量產啟動的時程再往後推移數月。
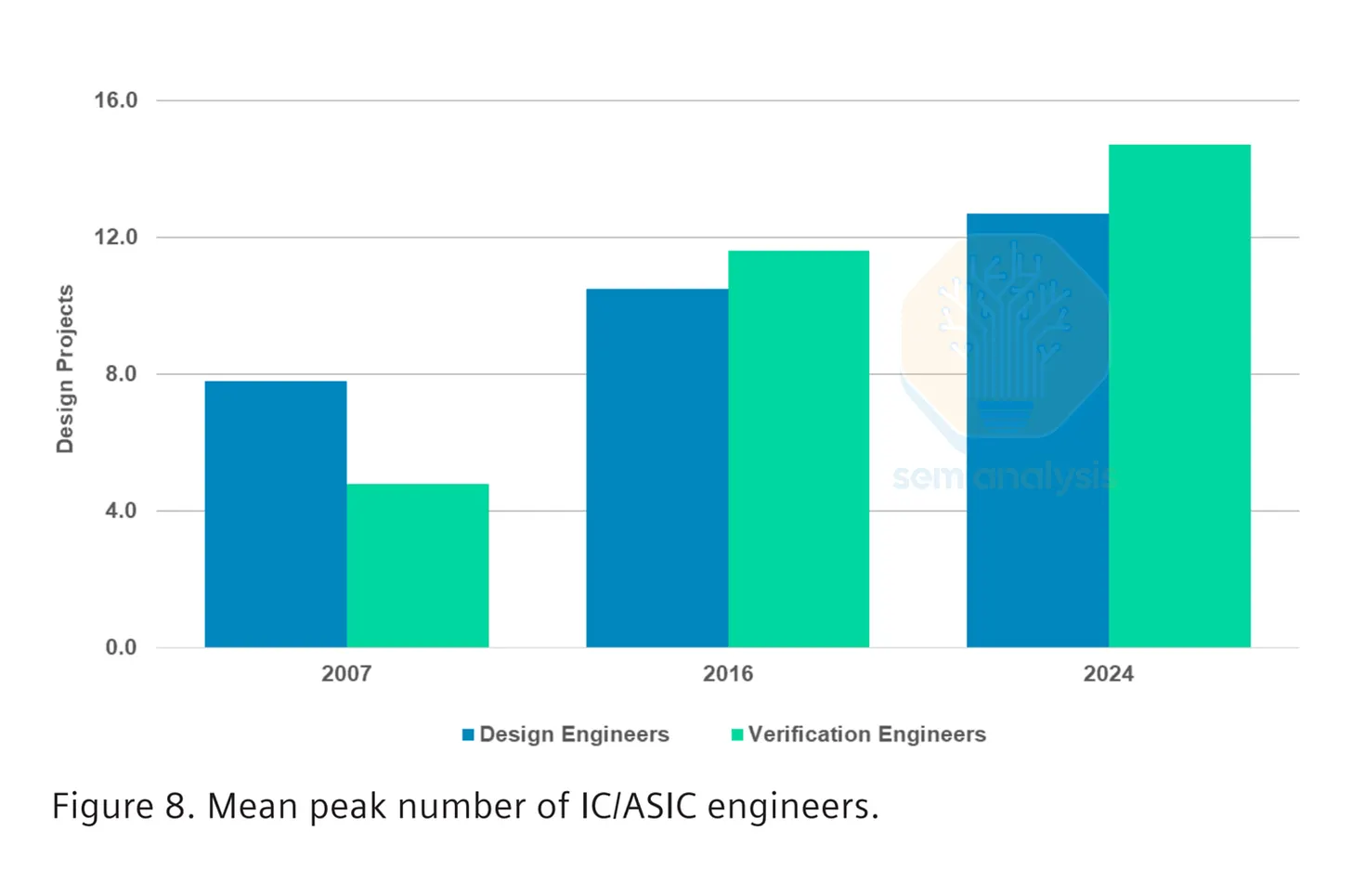
隨著設計愈趨複雜,測試愈來愈重要——必須確保晶片內所有模組能相互協作、各自正常運作。驗證(Verification)是在晶片投片前證明設計完全符合規格的過程,根據設計複雜度,這道工序如今可能佔去整個專案總工時的七成。驗證工程師是晶片開發領域中成長最快的職類,業界的招募速度始終追不上需求。
來源:Siemens
晶片複雜度每年約以 50% 的速度增長,由新製程節點與更大型的 SoC 驅動;然而設計生產力每年僅提升約 20%。這道生產力落差意味著,每一代新矽晶片都需要呈指數級增加的工程投入、更多算力,以及更精密的自動化工具。
半導體業能否持續打造出更強大的晶片,依靠的不只是物理定律或微影技術,更在於 EDA(電子設計自動化) 軟體。這些工具將人類的設計意圖轉化為可量產的矽晶片。沒有 EDA,1980 年代中期以後設計的每一顆晶片都不可能存在。
這篇入門指南將帶你認識半導體業中的 EDA。在第一部分,我們將走完從 RTL(暫存器傳輸層) 程式碼——工程師實際撰寫的硬體描述語言——到製造完成、完成封裝的矽晶片的完整旅程。我們會點名具體工具、解釋權衡取捨,並說明為何 EDA 是科技業中最舉足輕重、卻最常被低估的領域之一。
第二部分,我們的 EDA 市場分析 將深入剖析 EDA 的商業面貌,介紹主要公司(Synopsys、Cadence、Siemens)的收入與商業模式,提供全面的市場分析,包括追蹤中國的 EDA 發展、IP 授權與委外設計服務,以及超大規模雲端業者自行客製 ASIC 設計(COT)趨勢。
第三部分將評估 AI 如何顛覆 EDA 產業,涵蓋從新創公司、工程師儀表板,到 NVIDIA 及三大 EDA 廠商的 AI 代理晶片設計流程。用 AI 加速器設計出超越人類的下一代 AI 加速器,是這個產業數十年來最令人振奮的發展。敬請期待這場即將到來的晶片設計革命。
▉ 歷史簡介:從美工刀到三巨頭

來源:Intel
1960 至 1970 年代,設計一顆積體電路意味著用手工繪製。工程師在方格紙上勾勒佈局草圖,技術員再將草圖轉描到一種叫 Rubylith 的紅色玻璃紙薄膜上,它貼合在透明的 Mylar 底片上。他們用美工刀和燈桌裁切薄膜,定義出晶片各層的形狀。完成的原版圖稿再以最高 100 倍的比例縮小,製成生產用的光罩。刀刃一滑,幾週的心血可能毀於一旦。這就是當時的標準設計流程,直到 Intel 8080 仍採用這套工法,上圖即為其 Rubylith 版型。
自動化的第一步出現在 1971 年——Calma 向 Intel 交付了 Graphic Design System(GDS),讓工程師可以在迷你電腦上數位化並編輯佈局。1978 年,Calma 推出 GDS II,其串流檔案格式成為光罩資料交換的事實標準。驚人的是,GDS II 至今仍是主流交換格式,與其現代繼承者 OASIS 並列,距今已近半個世紀。
EDA 產業的真正面貌,誕生於 1981 年——三家公司在幾個月內相繼創立:Daisy Systems、Mentor Graphics、Valid Logic Systems。這三家合稱 「DMV」,在設計流程的前段引入計算機輔助工程,涵蓋電路圖捕捉、模擬與邏輯驗證,全在專用工作站上執行。1980 年代末,三家公司先後遷移到 Apollo 與 Sun Microsystems 的標準 Unix 工作站,確立了以軟體為核心的商業模式,這正是 EDA 產業今日的面貌。
▉ 三巨頭的崛起
現代 EDA 市場由三家公司主導。Synopsys 於 1986 年由 Aart de Geus 與 GE 研究部門的同事聯合創立,1987 年推出 Design Compiler,這是第一套商業化的邏輯合成工具。邏輯合成將高階硬體描述自動轉換為優化後的閘級網表,是劃時代的突破,讓設計從手工擺放數千顆電晶體躍升到今日數十億顆的規模。Cadence Design Systems 於 1988 年由 SDA Systems 與 ECAD 合併成立,迅速成為 IC 佈局與擺放繞線工具的領導廠商。Mentor Graphics 是 DMV 三巨頭之一,於 2017 年以 45 億美元被 Siemens 收購,2021 年更名為 Siemens EDA,將深厚的驗證與實體設計能力納入 Siemens Digital Industries 旗下。
與早期的 Rubylith 時代相比,邏輯合成不僅加快了設計速度,更從根本上改變了設計的可能性。透過抽象化省去人工的閘級擺放,設計複雜度提升了數百萬倍,造就了今日擁有數十億顆電晶體的 SoC。
▉ 晶片設計瀑布流程
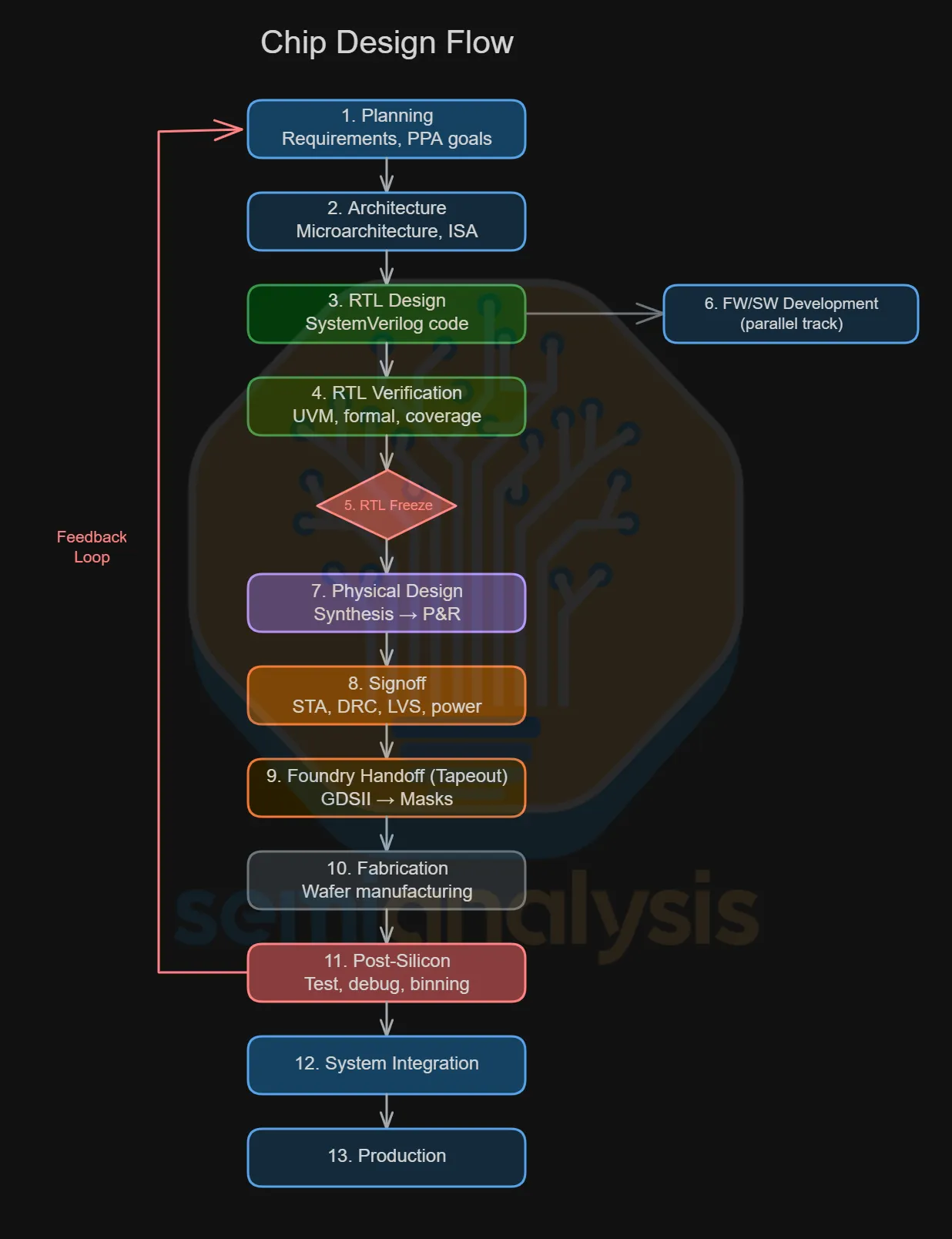
打造一顆晶片,是一場歷時數年的接力賽,共有十三棒。哪怕只有一次交接失誤,整個時程就可能滑落數月、甚至數季。下圖呈現了從白板空白到量產出貨的完整流程。本文將逐一說明 EDA 工具在設計流程中發揮作用的各個階段。
來源:SemiAnalysis
- 規劃:定義產品需求、目標市場,以及將約束所有後續決策的 PPA(功耗、效能、面積)目標。
- 架構:設計微架構,包括指令集選擇、快取層級結構、匯流排寬度,以及將晶片拆分為可管理單元的方塊圖。
- RTL 設計:以幾乎清一色採用 SystemVerilog 的硬體描述語言,撰寫實際的設計程式碼,規定每一個暫存器、多工器與狀態機的行為。
- RTL 驗證:透過數十億種情境的測試或形式化證明,確認 RTL 行為正確無誤,以測試平台或形式化證明實現。
- RTL 凍結:設計鎖定。不再允許功能性修改,僅允許通過嚴格變更審查的錯誤修復。
- 韌體/軟體開發(並行):韌體與軟體團隊在模擬器與 FPGA 原型上展開系統啟動,通常與實體設計並行進行,以節省數月時程。
- 實體設計:邏輯合成(將 RTL 轉換為閘級網表)、擺放(將邏輯閘配置到晶粒上)、繞線(連接各閘的導線)、平面規劃(為各功能模組分配晶粒區域)。
- 簽核:執行最終檢查,確認設計符合時序收斂(每個訊號準時到達)、功耗預算,以及 DRC/LVS(製造規則)的要求。
- 晶圓廠交付:完成的佈局以 GDSII 格式匯出,這份動輒數 GB 的藍圖供晶圓廠用於製作微影光罩,標誌著「流片」(tapeout)里程碑的達成。
- 製造:晶圓在晶圓廠歷時 3 至 4 個月製造完成,途經數十道製程工具的數千個加工步驟。
- 矽晶片後驗證:實際晶片從晶圓廠回廠。工程師在客製化電路板與探針卡上進行測試,除錯勘誤,並制定分級策略,將具不同良率與效能的產品分類為不同 SKU。此階段可能進行多次改版,同時以老化燒機與最終測試進行可靠性驗證。
- 系統整合:驗證後的晶片整合至電路板與封裝體,連接至儲存、網路等裝置,並完成驅動程式、BIOS 與作業系統的系統層級測試。
- 量產:隨需求擴大量產規模,持續優化良率並協調供應鏈。
以上是簡化的「瀑布式」視角。實際上,許多階段高度交疊、反覆迭代。驗證過程中發現的架構錯誤迫使 RTL 修改;實體設計中出現的時序違規則讓工程師重返關鍵路徑重新優化。現代 SoC 專案同時管理數十條這樣的回饋迴路,這正是 EDA 工具存在的原因——靠人工根本無法追蹤。
▉ 1. 規劃
晶片設計的第一步,是確立這顆晶片要扮演什麼角色。各設計部門通常專注於特定的晶片家族,從 CPU 與加速器,到功能更為基礎的系統控制器與嵌入式感測器,不一而足。產品需求與高階規格的制定,需參照當代市場的競品,並對目標市場進行競爭分析。
初期會提出若干概念草案,隨著計畫主持人(Program Manager)逐步整合來自各設計團隊、準備好可整合的 IP 模組導入時程,這些概念也快速演進。過去專案的事後回顧報告也會被納入參考,形成一套知識庫,用以判斷哪些方案可行、哪些在既定時間框架內過於激進。
此階段的核心高階指標是 PPACt:效能與功耗(通常以較上一代改善的百分比表示,並評估在競爭格局中的相對位置)、設計在特定製程節點上占據的矽晶片面積(直接影響成本),以及上市時機(決定產品是否具有設計時程與市場競爭力的雙重可行性)。在效能每幾年倍增的高速成長市場中,晚了一年可能就宣告計畫失敗。
可行性評估完成後,必須獲得管理層的核准才能正式啟動專案。每家公司的研發預算與工程資源都是有限的。由於路線圖中同時進行著多個在途專案,資源排程必須有嚴格的完工期限,讓工程師能及時釋出,投入下一個專案。提早與供應商溝通,預估每個設計所需的晶圓、記憶體與封裝需求,已成為確保產能的關鍵。
▉ 2. 架構佈局
架構佈局與規劃高度緊密相連,兩者往往同步進行設計空間探索。高階平面規劃圖為每個邏輯與 I/O 模組設定初始的面積邊界框。每個功能模組會被拆分為更小的元素,使其更易設計、並可在全局設計中重複使用。這些面積預算在設計週期中可能隨需求而調整擴大,例如指令集架構(ISA)加入新指令所需的額外運算元件,或 AI 加速器增加資料流加速器、拓寬矩陣乘法引擎等功能。
來源:Microsoft
各功能模組間的關係與網路晶片(NoC)頻寬需求會繪製成方塊圖,並依快取層級結構與早期效能模擬,決定記憶體匯流排寬度及 SRAM 面積預算。這些模擬被稱為設計空間探索(Design Space Exploration),傳統上透過針對性的實驗設計來進行,模擬各功能模組間的效能影響與交互關係,在大小、寬度與頻寬等維度上調整,找出效能提升的最大空間。
往後,這個步驟愈來愈多地借助 AI 加速,因為 PPA 最佳化具有可分配的獎勵函數,在多維輸入空間中容易驗證。Synopsys 的 DSO.ai 等第一方 AI 輔助探索工具,是各無晶圓廠設計公司內部嘗試利用 AI 加速路徑選定與規劃決策後相繼跟進的成果。我們將在本系列第三部分提供深入分析。
▉ 3. RTL 設計
完成架構規格後,工程師必須精確描述晶片的行為,在暫存器、資料路徑與組合邏輯的層次上進行。這份描述稱為 RTL(暫存器傳輸層)程式碼,是定義設計行為的語言,可同時被人類與合成工具讀懂。晶片設計流程中大多數的工程工時,都花在撰寫與驗證 RTL 程式碼上。以下逐一介紹 RTL 設計的各個面向。
訊號時序
在真實世界中,電晶體的切換並非瞬間完成。輸入訊號改變後,需要一段時間才能在輸出端產生穩定的訊號,這段延遲稱為傳播延遲,由兩部分組成:閘延遲(電晶體本身切換的速度)與線延遲(電訊號沿金屬內連線傳遞至下一個閘的時間)。在先進製程節點中,隨著電晶體切換速度提升而資料路徑因複雜設計而拉長,線延遲往往超過閘延遲,成為主要瓶頸。
![]()
SRAM 元件讀取波形。來源:MediaTek
數位晶片用時脈訊號同步所有運算。決定正確性的有兩個時序約束:建立時間(Setup time) 要求輸入資料必須在時脈邊緣到來之前穩定一段最短時間;保持時間(Hold time) 則要求資料在時脈邊緣之後仍保持穩定一段最短時間。時脈週期(頻率的倒數)必須足夠長,以容納整個設計中最慢的訊號路徑。這條最慢路徑稱為關鍵路徑(critical path)。若關鍵路徑需要 0.2 奈秒,而你的目標是 5GHz 時脈(週期同為 0.2 奈秒),設計就毫無餘裕,完全無法抵抗製程變異。這正是為何時序優化在晶片設計中消耗如此龐大的工程資源,並涉及效能與複雜度之間無數的取捨。
狀態元件
組合邏輯可以從輸入計算出輸出,但要建構計數器、處理器流水線級或協定引擎等實用功能,還需要與記憶體結合。這些記憶暫存器以正反器(flip-flop) 實現。正反器在每個時脈邊緣捕捉並保持一位元的資料,充當微型的單位元記憶體。多個正反器與組合邏輯串聯,形成有限狀態機(Finite State Machine,FSM),每個時脈週期步進一個定義好的狀態序列,就是所謂的時序邏輯,是晶片得以進行運算的基礎。RTL 正是對「資料如何在每個時脈週期內於暫存器與組合邏輯之間流動」的抽象描述。
撰寫 RTL
RTL 以硬體描述語言(HDL)撰寫。當今主流選擇是 SystemVerilog,它是原版 Verilog 語言的延伸,為設計與驗證兩端均新增了功能。較舊的替代方案 VHDL 至今仍見於航太與傳統應用。設計者撰寫 RTL 時,需規定每個時脈邊緣的行為:資料在暫存器間流動的方式、算術運算的執行,以及狀態機的轉換。合成工具(見下一節)再將這份描述轉換為實際的閘與電晶體。
RTL 撰寫完成後,會先通過「程式碼審查」(linting)——一種靜態分析,捕捉程式錯誤、競爭條件與語法問題,不需要模擬即可快速完成。Synopsys 的 VC SpyGlass 是業界標準的程式碼審查工具,能標記可能導致矽晶片間歇性失效的細微問題。這相當於晶片設計界的編譯器警告,只是後果代價要昂貴得多。
IP 整合
在多數現代 SoC(系統晶片)設計中,真正自行設計的客製 RTL 邏輯大約只占 20 至 30%。非關鍵元件重用舊有設計更為經濟,其餘部分由授權取得的 IP 模組補足——這些是向第三方廠商購買的預先設計、預先驗證模組。ARM 提供處理器核心、GPU 及其他 IP;Synopsys 的 DesignWare 提供 USB、PCIe、DDR 記憶體控制器及數百種其他介面模組;Broadcom 的高速 I/O 也可選用;更小型的 IP 廠商則銷售從 GPIO 介面到加密加速器的各式模組。
IP 授權是市場經濟的結果。若要從頭自行設計一套 PCIe Gen 6 控制器,需要專門組建一支 I/O 設計與驗證工程師團隊,逐一驗證與 PCI-SIG 規格的相容性。授權一套成品的成本遠低於此,且已預先通過規格驗證。然而,IP 整合本身並非易事——這部分我們將在付費訂閱內容中為讀者深入說明。
▉ 4. RTL 驗證
RTL 程式碼隨後進入驗證流程,目的是找出並修正所有設計錯誤。驗證透過模擬實現:在軟體中執行設計,施加激勵訊號,並檢查輸出結果。目前市場上有三大商業模擬器,依普及程度排列:
- VCS(Synopsys):市場領導者,以原始模擬速度著稱,並與 Synopsys 其餘工具鏈高度整合。
- Xcelium(Cadence):Cadence 的模擬器,在多核心效能與混合訊號模擬上具競爭力。
- Questa(Siemens EDA):在進階除錯與覆蓋率分析方面表現突出,並深度支援 UVM。
大多數大型晶片公司至少授權其中兩套工具。在複雜 SoC 上執行一輪包含數萬個測試案例的完整回歸測試,每次可能消耗數千個 CPU 核心小時。如今僅憑自建的本地驗證伺服器往往不夠,各團隊通常在流片截止日前的衝刺期間,藉助 AWS 和 Azure 上的雲端模擬來補充短期爆量需求。這個過程所產生的資料量也相當驚人,光是一顆晶片的全部定義與測試項目,就需要多個 PB 的磁碟空間來存放。
如前所述,在晶片設計公司中,驗證工程師的人數通常超過任何單一職類。隨著晶片日益複雜,需要相互驗證的項目只會更多,對驗證人員形成沉重負擔。我們將在付費訂閱內容中深入探討這對實際晶片設計工作的意義。
驗證流程分為兩條路徑:一端是標準的 DV 功能測試,另一端是以數學證明為基礎的形式驗證。
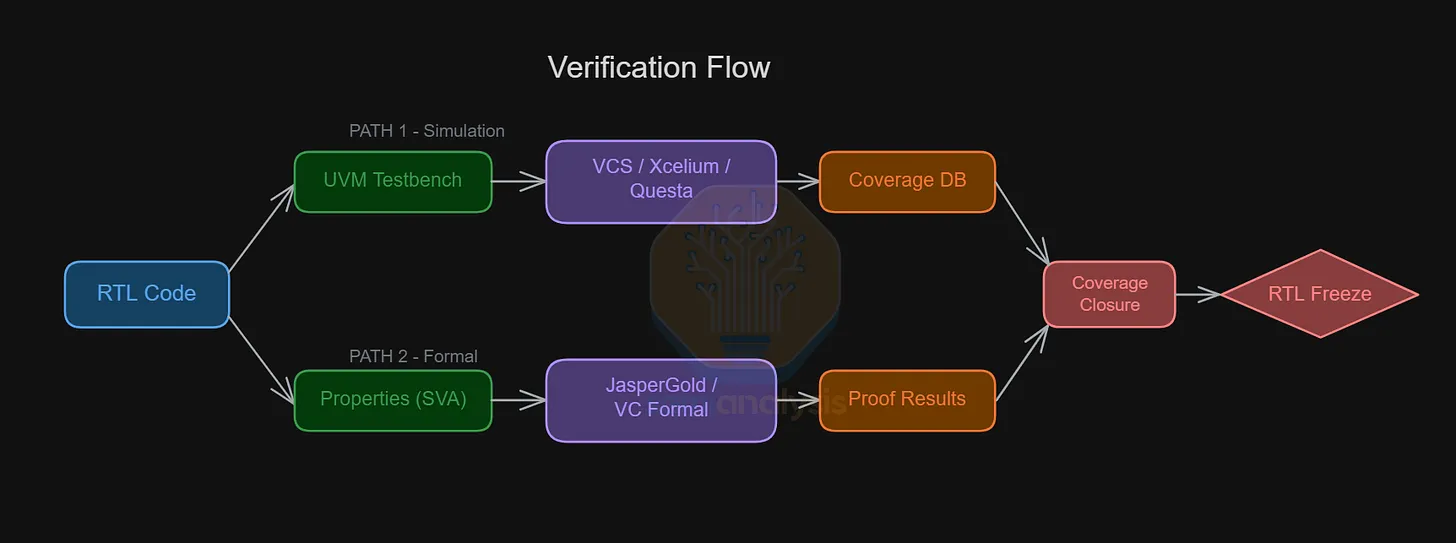
來源:SemiAnalysis
UVM 測試平台
RTL 模擬的架構遵循 UVM(統一驗證方法學,Universal Verification Methodology)。這是一套業界標準的 SystemVerilog 函式庫與方法論,用以建立可重用的測試平台。在 2011 年 Accellera 將 UVM 標準化之前,各團隊各自維護一套測試平台架構。UVM 的出現凝聚了整個產業,定義了一組通用元件:
- Sequencer(定序器):產生交易序列並傳送給 Driver,測試情境在此定義。
- Driver(驅動器):將抽象交易(例如「送出一個 32 位元組的讀取請求」)轉換為設計輸入腳位上的訊號波動。
- Monitor(監測器):被動監測設計介面上的訊號,並還原出已發生的交易。
- Scoreboard(計分板):對比參考模型的預期輸出與設計的實際輸出,任何不符均標記為錯誤。
測試平台用於約束隨機驗證(constrained random verification)。工程師不需要手工撰寫每一個測試案例,而是定義約束條件,例如合法的位址範圍、有效的封包格式與協定規則,再由工具在這些邊界內隨機產生數百萬種輸入組合。這種方法能找出刻意指向性測試可能遺漏的邊界錯誤。約束隨機回歸測試因樣本空間龐大而消耗大量資源,但在錯誤偵測上通常比手寫定向測試更有效。
形式驗證
形式驗證採取截然不同的方法。它不是對特定輸入施加激勵並檢查輸出,而是使用 SAT 求解器與模型檢查器等數學證明引擎,對所有可能的輸入與所有可能的狀態序列,窮舉證明某個設計性質是否成立。若該性質可被違反,工具會給出一個具體的反例,精確說明違反的路徑。形式驗證以性質(property)為驗證對象,通常採用 SystemVerilog 斷言(SVA) 來定義預期行為。
領先工具是 JasperGold(Cadence)與 VC Formal(Synopsys)。形式驗證在協定合規性(例如握手訊號不得連續拉高超過 3 個週期)、控制邏輯正確性,以及安全性質(例如此暫存器僅限具有更高權限的軟體存取)等方面表現優異。然而其弱點在於可擴展性:在匯流排位元寬度較大的資料路徑密集型設計上,形式引擎往往達到容量極限。實務上,形式驗證與模擬相輔相成:形式驗證對目標模組的關鍵性質進行窮舉式驗證,模擬則以統計信心水準覆蓋整顆晶片。
▉ 5. RTL 凍結
確認驗證完成與否,工程師需要參照幾項覆蓋率指標——對各測試平台已覆蓋範圍的量化衡量。共分兩大類:
程式碼覆蓋率衡量結構完整性:
- 行覆蓋率:RTL 的每一行是否都已被執行?
- 分支覆蓋率:每一個可能的分支是否都已被走過?
- 切換覆蓋率:每個訊號是否都在 0 與 1 之間切換過?
- FSM 覆蓋率:每個有限狀態機的每個狀態與每條轉移路徑是否都已被走過?
功能覆蓋率衡量設計意圖:
- 我們實際測試了關心的情境嗎?
- 是否有已知的邊界案例需要特別關注?(例如:同時對同一位址寫入、FIFO 緩衝區已滿且同時有中斷待處理)
- 需要取樣哪些特定變數才能測試到這些情境?SystemVerilog 中定義的 Covergroup 明確描述了這些測試案例,並追蹤回歸測試是否命中了特定變數。
覆蓋率收斂(Coverage closure) 是驗證流程的最後一道關卡。90% 的測試案例通常能迅速通過,但要消化剩餘的 10% 功能覆蓋率,需要付出大量心力——有時需要花費數週撰寫針對性測試,同時在其他測試中添加或調整約束與排除條件。測試案例愈具體複雜,所需的領域知識就愈深。設計公司會借助過去大量專案累積的經驗,優先排序最重要的測試案例。
當所有覆蓋率目標達成,且目標嚴重程度以上的未解決錯誤歸零,專案的 RTL 即宣告凍結。這個正式里程碑稱為 RTL Freeze,意味著不再允許對 RTL 進行功能性修改。從此之後,任何修改都必須經過稱為工程設計變更(Engineering Change Order,ECO) 的正式流程,需重新驗證並進行等效性檢查。RTL Freeze 確保下一個步驟——實體設計——有一個明確的基礎可以依循,讓前端設計與後端實體實作得以分離。
驗證常被視為晶片設計中不那麼光鮮的一面,但它對新架構的開發至關重要。設計一顆晶片容易,難的是確認你的設計在所有可能情境下都能正確運作。
▉ 6. 韌體與軟體開發
晶片開發本已歷時數年,軟體團隊根本等不到矽晶片到手才開始撰寫軟體。作業系統、韌體堆疊與驅動程式套件必須在第一批晶片從晶圓廠回來之前大致備妥。為了在硬體開發期間同步進行軟體開發,工程師倚賴矽前硬體模擬(Pre-Silicon Hardware Emulation):晶片的 RTL 設計被映射到大型 FPGA 陣列上,以 50MHz 的速度執行晶片功能。FPGA 中的可程式化邏輯元件以近似每個設計邏輯配置的方式繞線,使這些模擬器的執行速度達到純軟體 RTL 模擬的 1,000 倍。

來源:Synopsys
兩大主流平台是 Synopsys 的 ZeBu 與 Cadence 的 Palladium。Synopsys 最新的 ZeBu-200 叢集最多可模擬 230 億顆邏輯閘,執行效能是上一代的 2 倍。Cadence Palladium Z3 則可擴展至 480 億顆邏輯閘的設計,速度是 Z2 世代的 1.5 倍。這些系統讓韌體團隊可以在矽晶片到手前數月,就在模擬器上開機啟動 Linux、測試韌體並進行軟體驗證。
▉ 7. 實體設計
到目前為止,晶片仍只以高階 RTL 描述的形式存在。在實體設計開始前,必須先完成一個關鍵的轉換步驟。
邏輯合成
邏輯合成將 RTL 程式碼轉換為閘級網表(gate-level netlist),即從晶圓廠標準元件庫中選取邏輯閘、描述其連接關係的一份映射圖。合成工具解析 RTL 程式碼,判斷出哪種邏輯閘的組合、以何種順序相連,才能實現 RTL 所描述的功能。
此外,合成器還要在設計的限制條件下優化網表,在時序(此電路的邏輯閘能在 4 個時脈週期內完成運算嗎?)、面積(我能在架構描述設定的面積框內塞入多少邏輯閘?)與功耗(這些邏輯閘的動態切換與靜態漏電共消耗多少瓦?)三者之間取得平衡。壓縮重複邏輯、跨功能共享邏輯閘、對功能進行重定時(retiming)以降低關鍵路徑負擔等技術,可在一定程度上緩解這些相互衝突的目標。工具會在數千種替代實作中探索最佳的取捨組合。
來源:Synopsys
Synopsys 的 Design Compiler 是業界鼻祖,也是至今仍居主導地位的合成工具,陸續推出 NXT 與 Ultra 等版本,整合度與功能持續提升,並搭配圖形介面 Design Vision 供工程師評估合成流程。Cadence 提供 Genus 作為其合成工具。Synopsys 目前主推 Fusion Compiler,將合成與擺放繞線整合進單一統一流程,支援 RTL、時序與佈局之間的交叉探查。統一 EDA 流程的細節將在下文詳細介紹。
等效性驗證
RTL 合成為閘級網表後,必須確認合成工具沒有引入錯誤。為此,設計以等效性驗證(Equivalence Checking) 進行數學上的正確性證明:這是一種形式技術,用以逐一輸入、逐一輸出地驗證設計的兩種表示形式(RTL 與閘級網表)在功能上完全相同。Formality(Synopsys)與 Conformal LEC(Cadence)是標準工具。
等效性驗證不只在合成後執行,而是在每一個重大轉換步驟後都要執行:時脈樹插入、掃描鏈縫合、繞線優化,以及每一次 ECO 之後。每次轉換都可能引入錯誤,等效性驗證因此是一張安全網,捕捉工具自身引入的錯誤。
邏輯閘
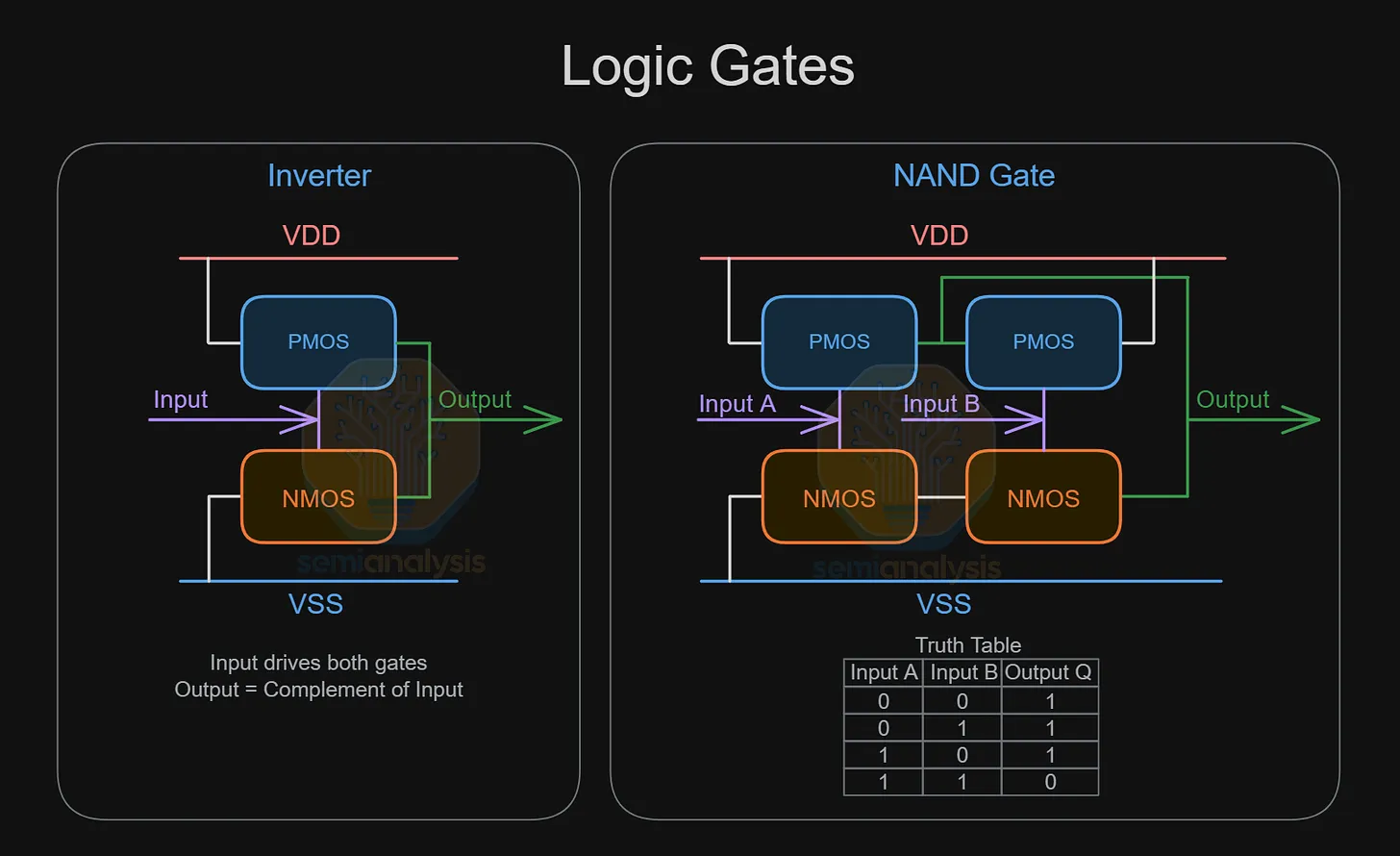
來源:SemiAnalysis
合成器從標準元件庫中選取一系列邏輯閘,每個邏輯閘執行一種布林函數,將特定的二進位輸入組合轉換為輸出。輸入與輸出的所有排列以真值表呈現,如上圖所示。七種基本邏輯閘包括 INV、NAND(如上圖)、AND、OR、NOR、XOR 與 XNOR。標準元件中的電晶體佈局即在現實世界中執行這些運算,輸出訊號電壓拉高至 Vdd 表示「1」,或下拉至 Vss 表示「0」。
標準元件庫
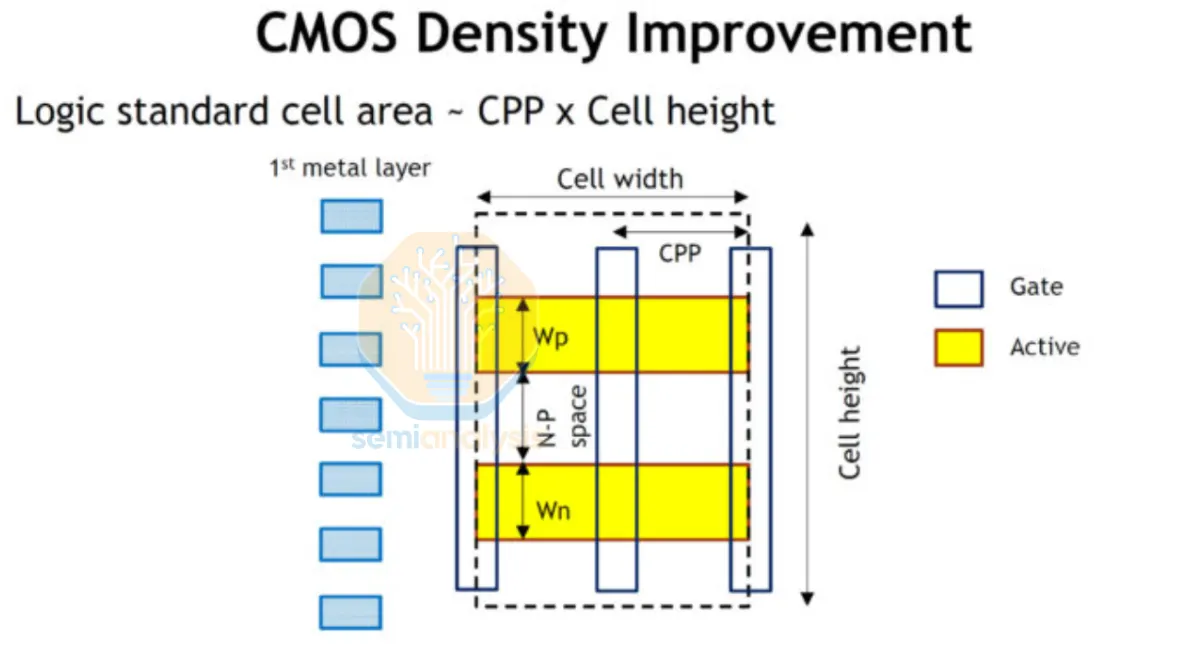
來源:TSMC
上述邏輯閘並非每次都從頭設計,而是從標準元件庫中調用。標準元件庫是一套由晶圓廠或第三方 IP 廠商提供、預先設計並預先表徵的邏輯建構模組目錄,且完全遵守設計規則。每個元件具有固定高度與可變寬度,像磚塊砌牆般整齊地在晶粒上橫向排列成行。這種標準化、有序的佈局——上方為 PMOS、下方為 NMOS 的兩個電晶體位置,以及固定間距的電源供應——對於實現自動化擺放與繞線至關重要。
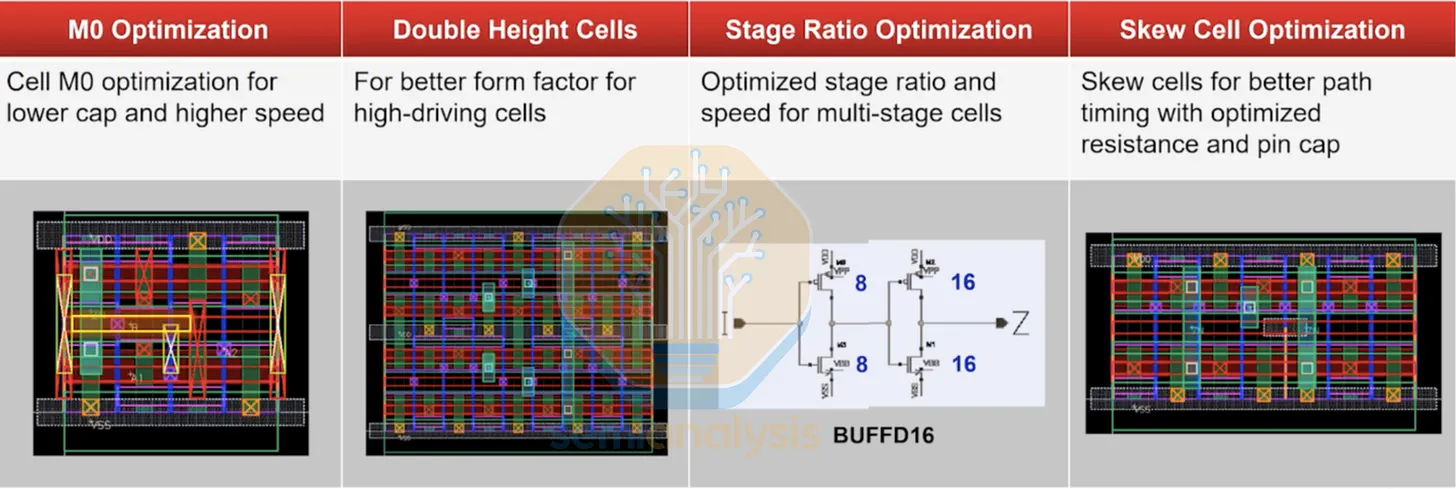
除了基本邏輯閘,標準元件庫還提供具有進階功能的複雜元件,將邏輯運算組合成更高階的函數,在設計中被反覆使用。與晶圓廠關係密切的公司也可以為這些複雜運算自行設計客製元件。按複雜度遞增排列,範例包括:AOI、OAI、暫存器、多工器、D 型正反器與全加器。設計中還散布著各種特殊用途元件,例如 IO 墊片元件、Tap 元件、填充元件與去耦電容元件、高低電位固定元件、電源與時脈閘控元件,以及在多電壓域之間傳遞訊號的電平轉換器。每個製程節點也都附有 SRAM 巨集編譯器,用以產生靜態隨機存取記憶體模組——這是邏輯製程中密度最高的記憶體元件。
以 TSMC N2 這樣的先進節點為例,一套現代標準元件庫包含數萬個獨立元件。每種邏輯閘都有多種佈局選項,依導線繞線方式與訊號腳位可及性而有所不同。每個邏輯閘也提供多種驅動強度選項,驅動強度較高的元件用於其輸出需要驅動多個輸入訊號的場合,但有較高的漏電功耗,因此需要選擇性使用。現代 TSMC 製程節點提供超過 6 種門限電壓選項,以精細調節訊號可靠性與功耗。Intel 18A 初期的問題之一,就是只有 4 種 VT 選項(Intel 實際只用了 3 種),而 TSMC 有 6 種,意味著即便 Intel 在特定點的效能更佳,其設計在所有 VT 的帕雷托最優曲線上仍較難覆蓋。Intel 的 18AP 已就此改進。
合成工具依據時序與功耗約束,為每個元件挑選適當的尺寸。面對數百萬種可能的組合,合成與實體設計中的 EDA 工具都是必不可少的導航器。
隨著摩爾定律放緩,採用新型面積縮放技術的新製程節點進一步加劇了佈局複雜性。TSMC 的 N3 FinFlex 與 N2 NanoFlex 將不同元件高度的標準元件混合排列,增加了又一層設計約束。各節點還提供多種庫選項,例如高密度(HD)與高效能(HP),具有不同的標準元件尺寸與功耗特性。對於環繞閘(Gate All Around)製程(SF3、18A、N2),每種標準元件高度還提供多種奈米片寬度選項。設計者可以為晶片的不同區域混搭不同的庫,以從新製程中提取最優的 PPA。以 Apple 為例,其高效能 CPU 核心採用 TSMC 的 3-2 FinFlex,晶粒其餘部分則使用密度更高、功耗更低的 2-1 FinFlex 庫。
標準元件庫是晶圓廠與晶片設計者之間最主要的商業介面。它不僅編碼了邏輯函數,更將晶圓廠的製造能力、設計規則與製程特性轉化為 EDA 工具可消費的形式。當無晶圓廠公司將設計「移植」至新晶圓廠時,遷移標準元件庫是第一個、也是影響最大的步驟,並連帶觸發整個工具流程最大量的重工。
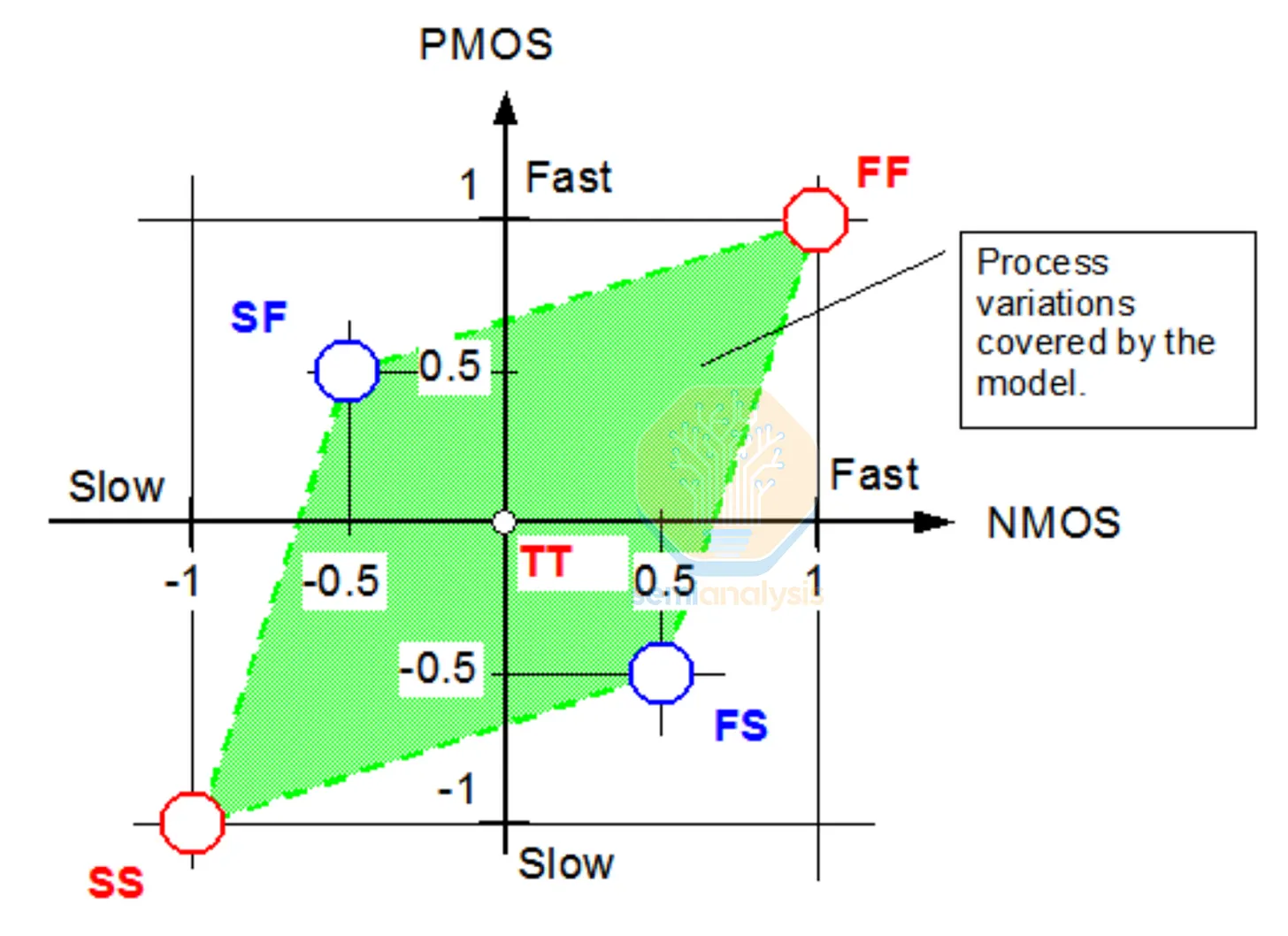
製程角隅
實體設計工具還必須考量真實世界的影響,尤其是製造過程中的變異性。元件的速度與功耗,會因製程(Process)、電壓(Voltage)與溫度(Temperature)的變化而顯著偏移,因此標準元件庫針對一系列 PVT 角隅進行表徵,如下圖所示。
來源:Keysight
TT(典型-典型)是名義情況。FF(快-快)表示 NMOS 與 PMOS 電晶體均比標準值更快。SS(慢-慢)表示兩者均更慢。FS 與 SF 則捕捉 NMOS 與 PMOS 之間的偏斜情況,這種情況尤其棘手,因為它以對稱角隅所沒有的方式影響電路平衡。
電壓圍繞名義供應值浮動。以名義值 0.75V 為例,角隅可能為 0.675V(-10%)與 0.825V(+10%)。電壓較低意味著切換速度較慢,功耗也較低。溫度範圍則取決於應用場景:消費性晶片可能覆蓋 0°C 至 105°C,而汽車等級的庫則必須從 -40°C 到 125°C 全面表徵。設計必須在慢速角隅下滿足時序要求,同時在高漏電角隅下維持功耗預算。
金屬內連線
標準元件定義了金屬內連線底部的主動電晶體層。最低的金屬層 M0 與 M1 用於元件內部,連接電晶體與接腳。這些是細而高阻抗的導線,適合元件內的短距離,但不適合在整顆晶粒上繞線傳遞訊號。相鄰金屬層的走線方向相互垂直,奇數層走南北向,偶數層走東西向。
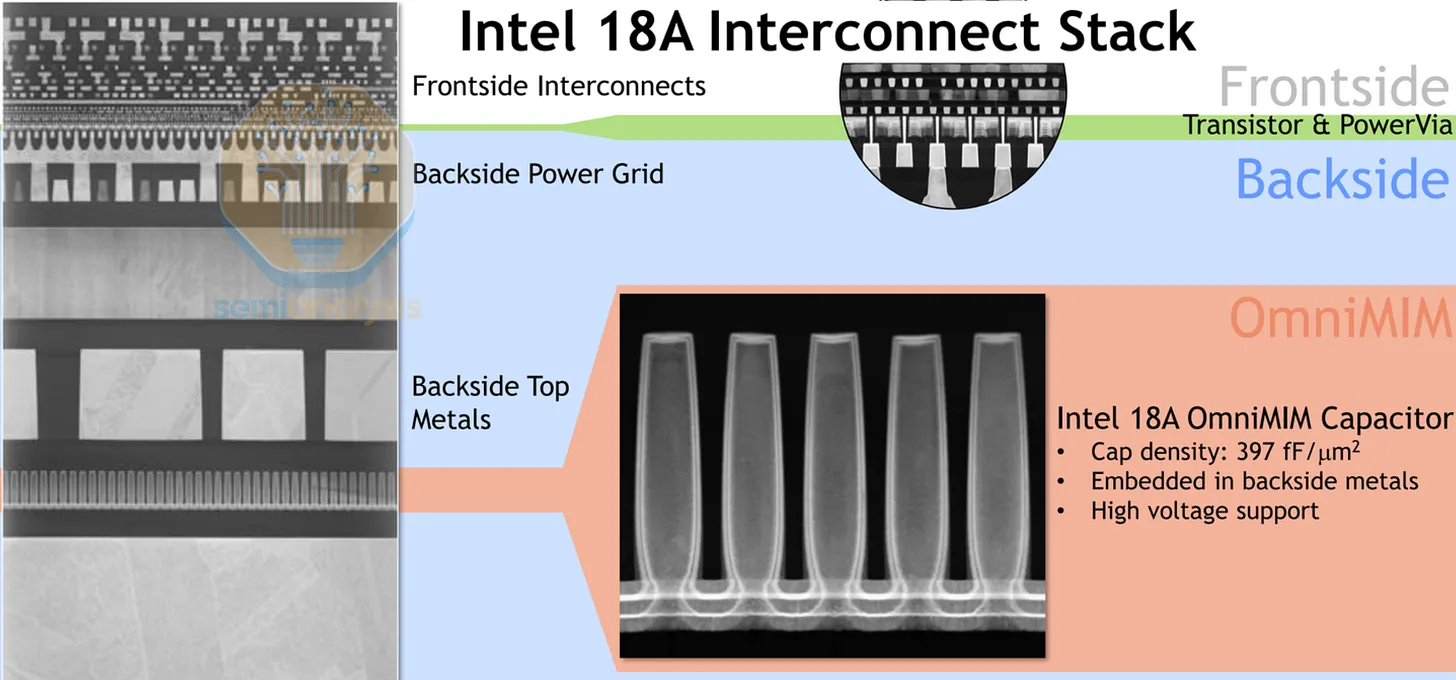
來源:Intel
半全域金屬層(M3 至 M5)負責模組層級的繞線,在一個功能單元內部連接各標準元件。這些金屬層逐漸變厚、變寬,降低長距離走線的電阻。頂部最厚的金屬層則保留給電源分配網路與全域時脈樹使用。整顆晶片的金屬層總數取決於設計複雜度,從低成本行動 SoC 的 10 層到高效能 AI 處理器的 19 層不等。如上圖 Intel 18A 所採用的背面電源輸送(Backside Power Delivery)方案,將電源與訊號線分離,為繞線工具開拓了另一個維度,同時降低了寄生電容與訊號干擾。
製程設計套件(PDK)
上述所有參數均由晶圓廠在製程設計套件(PDK)中詳細提供。這份密集的文件、模型與規則包,將晶圓廠的製造製程轉化為 EDA 工具可理解的語言。
每套 PDK 包含以下資訊,各有其業界標準檔案格式:
- LEF 檔(函式庫交換格式):提供標準元件的實體描述,包含腳位位置、金屬阻擋(需避開的區域)與元件邊界。擺放繞線工具使用 LEF,因其包含了足以定位元件並連接導線的幾何資訊。
- LIB 檔(Liberty 格式):包含時序弧(定義訊號傳播與衰減所需的時間)、功耗表,以及抗雜訊資料。每種 PVT 角隅組合都有對應的獨立 .lib 檔案。
- SPICE 模型(積體電路模擬程式):捕捉電晶體的詳細類比行為,例如門限電壓、漏電電流、電容,以及這些參數在製程角隅間的偏移。電阻、電感與電容等被動元件的模擬模型也可能一並提供。
- 參數化元件(P-cell):用於類比 I/O 區域,依設計者可調整的特定變數產生電晶體尺寸,比為每種不同尺寸逐一繪製元件要高效得多。
- 寄生效應提取表:告知提取工具如何計算佈局中每條導線與通孔的電阻與電容。這些資料以多種角隅提供,涵蓋 RC-max(最差情況慢速內連線)與 RC-min(最佳情況快速內連線),以反映製造變異。
- 設計規則手冊(DRM):包含數千條幾何約束,例如最小線寬、形狀間距、包圍規則、阻擋與密度要求,以及實體驗證的相關參數。
GDS(GDSII 串流)佈局參數也可能提供,呈現每一顆電晶體與金屬層的完整、精確實體佈局,包括擴散區、多晶矽閘、接觸點與通孔。這份檔案最終將提交給晶圓廠進行流片。
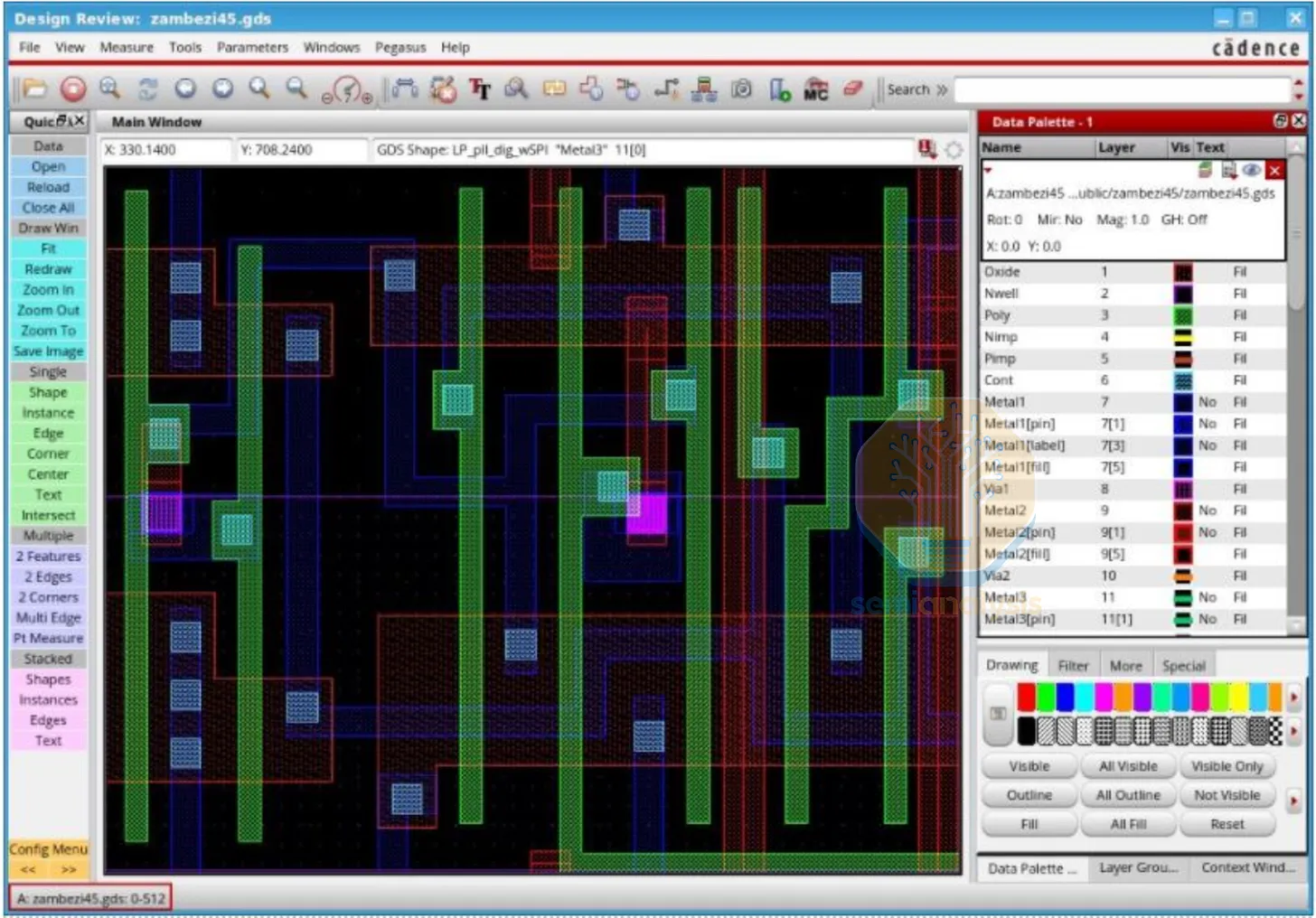
來源:Cadence
在 GDS 瀏覽器中看到的標準元件。每種顏色代表不同的製造層:多晶矽閘(紅色)、金屬內連線(藍色),以及各層之間的垂直接觸點與通孔(藍色方塊)。
PDK 版本
製程開發期間,客戶開始設計測試晶片並了解製程特性,因此 PDK 在邁向 1.0 量產版本的過程中會歷經多次修訂。主要的 PDK 里程碑版本如下:
- PDK 0.1 / PDK 0.3:完全基於 TCAD(技術計算機輔助設計)模擬建構,尚無真實矽晶片資料,用於早期架構探索與路徑選定,不確定性範圍較大。僅透過聯合開發協議(JDA)提供給錨定客戶,時間在量產前最多 2 年。標準元件尺寸已確定,但此階段的元件庫仍屬基礎。
- PDK 0.5:整合了來自短迴路晶圓與初期測試晶片的早期矽晶片資料,是真正晶片設計的起點(從測試晶片開始)。模型已大幅精煉,但 PVT 角隅覆蓋仍不完整。標準元件庫持續增長但尚未定案。一般晶圓廠客戶從此階段開始獲得存取權限。
- PDK 0.9:提供涵蓋所有 PVT 角隅的完整矽晶片表徵。接近最終版本的實體驗證表套件已備妥,並針對數百萬個測試結構進行驗證。所有主要 EDA 廠商均已提供完整支援,IP 也已就位。
- PDK 1.0:最終量產就緒版本。包含所有 Vt 變體與電路模型的完整標準元件庫均已提供。量產流片使用的就是這個版本。PDK 1.0 是晶圓廠宣告製造就緒的重要里程碑。
在各主要版本之間,晶圓廠會發布點版本更新,持續收緊設計規則、縮小模型不確定性,並加入從實際製造資料中發現的 DFM(可製造性設計)熱點規則。
PDK 授權與存取
晶圓廠 PDK 普遍受 NDA 保護,存取權限透過嚴格的分層制度管控,反映了商業關係與 IP 安全的雙重考量。
- 第一層:錨定客戶 / JDA 客戶(例如 Apple 在行動端、AMD / NVIDIA 在高效能運算端)。這些公司深度參與製程技術的定義與共同開發,在量產前 3 年以上即獲得存取權限。他們推動設計規則的演進,甚至可能「出資」給晶圓廠開發特定製程特性,以換取先行優勢與最深層的協作。
- 第二層:EDA 與 IP 合作夥伴。Synopsys、Cadence、Siemens EDA 與 Arm 等 IP 廠商提前獲得 PDK,用於工具驗證與 IP 開發。他們的標準元件庫、記憶體編譯器與介面 IP 必須通過認證並備妥,供無晶圓廠設計公司使用,這需要數個月的工程前置時間。
- 第三層:一般晶圓廠客戶。這些公司在成熟製程上設計晶片,不參與製程開發,只能接受既有設計規則。
- 第四層:學術與研究機構。受到嚴格限制。大學可能只獲得有限的 PDK 子集用於研究,且通常是在製程成熟後多年才有機會取得。
即便是第一層客戶,也無從得知晶圓廠的實際製造配方。晶片設計者看到的是電氣特性,無需了解具體的摻雜分布、製程溫度或蝕刻化學。PDK 作為抽象層,讓無晶圓廠模式得以運作,在晶圓廠與客戶之間保護各自的 IP。
PDK 時程:Intel 18A
- 2022 年 9 月:PDK 0.3 已交付早期設計客戶,測試晶片正在設計中,預計年底流片。
- 2023 年 3 月:與主要客戶分享 PDK 0.5 工程版本,預計數週內發布最終量產版本。
- 2023 年 9 月:PDK 0.9「即將推出」,18A 的多個測試晶片與穿梭流片服務正在廠內運行,包括內部與晶圓代工客戶。
- 2024 年 7 月:Intel 向晶圓代工客戶發布 PDK 1.0。
- 2026 年 1 月:Intel 內部的 Panther Lake CPU 在 18A 製程上正式發布。
開源 PDK
晶圓廠 PDK 是嚴密守護的機密,極少有人能接觸到。迄今為止,僅有少數量產 PDK 以完全開源的形式發布。2020 年,Google 與 SkyWater Technology 合作,發布了 SKY130 PDK——一套針對 SkyWater 130nm 製程、完整可量產的設計套件。SKY130 最初由 Cypress Semiconductor 開發,包含 SPICE 模型、DRC/LVS 表套件、標準元件庫與 IO 元件,也就是從 RTL 到製造矽晶片所需的一切,以 Apache 2.0 授權發布於 GitHub。GF180MCU 與 iHP130 同樣開源,且技術年代相當或更早。
儘管技術已逾 20 年,這些 PDK 對教育、開源研究,以及訓練實體設計開源模型而言至關重要。開源 EDA 生態系包含用於擺放繞線的 OpenROAD,以及用於自動化流程編排的 OpenLane。Google 也資助了多次多專案晶圓(MPW)穿梭流片,免費製造社群設計的晶片,讓學生得以在不需購買任何商業授權的情況下,完成從 RTL 到 GDSII 的完整流程。遺憾的是,Google 已撤回對這些計畫的資助。更多相關資訊請參閱此連結。
實體設計工具與功能
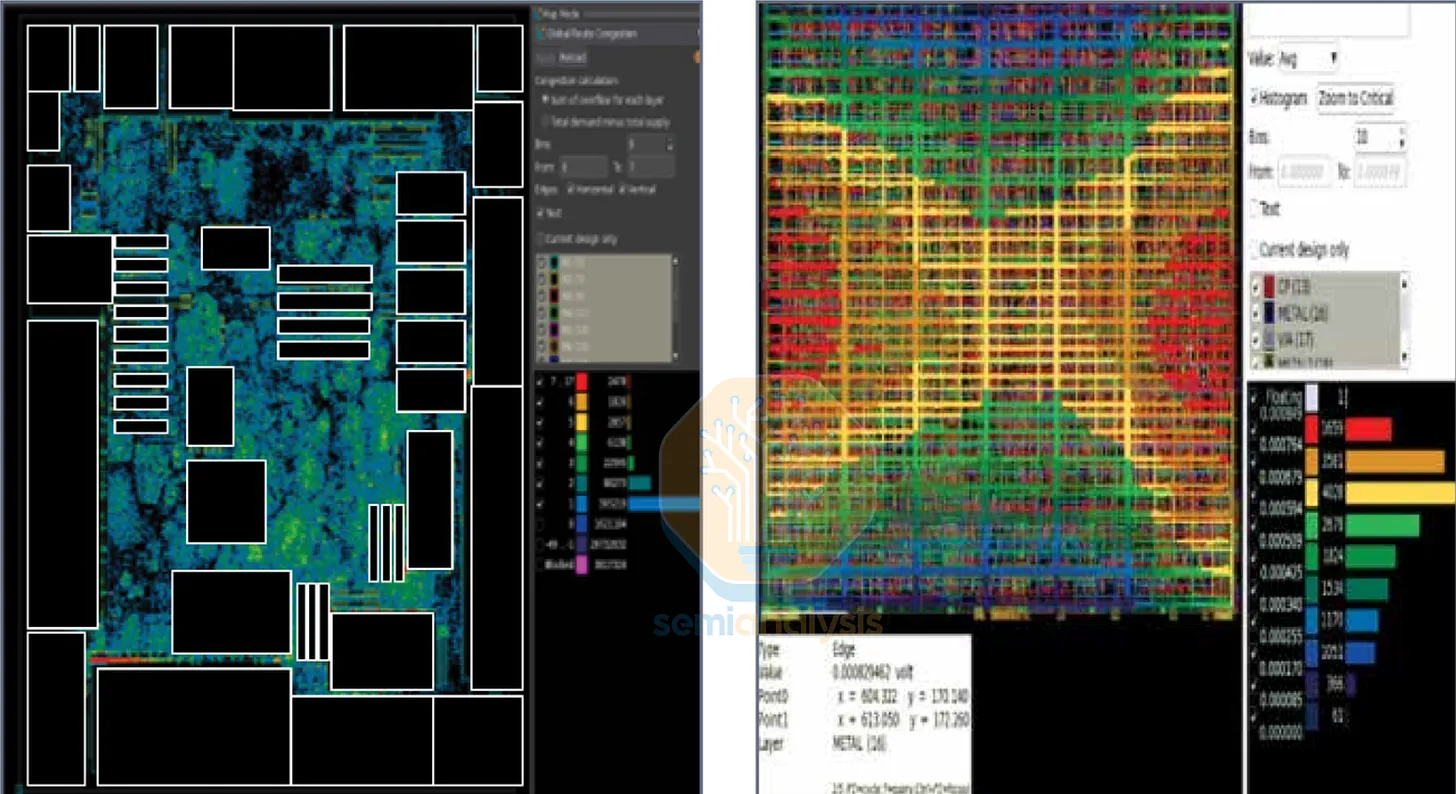
來源:Synopsys
兩大主流實體設計平台是 Synopsys 的 IC Compiler II 與 Cadence 的 Innovus,幾乎所有當今在先進製程節點流片的晶片都出自這兩套工具。選擇哪套工具,往往取決於團隊最熟悉哪一套——數十年、數十個專案積累的機構知識,讓換工具的成本高昂且不易。這些工具整合了上述所有參數與考量,連同已合成的網表與晶圓廠 PDK,產出完整的 GDSII 佈局以供流片。工程師使用這些 EDA 工具完成以下工作:
- 平面規劃(Floorplanning):定義晶片的實體輪廓與內部組織,類似於決定一棟建築所有牆壁與房間的精確位置,並依據上述高階架構規劃進行。大型巨集模組(SRAM、PLL、類比 IP)在此確定位置,IO 腳位也在晶片邊緣標示配置。
- 電源規劃(Power Planning):電源分配網路(PDN) 負責將供應電壓輸送至晶片上的每一顆電晶體。水平與垂直的電源條帶配合通孔堆疊,形成電源格網。PDN 必須處理多個電壓域以支援功耗效率分區,並能選擇性關閉閒置區域的電源(稱為電源閘控)。目標是最小化導線電阻所造成的 IR 壓降,電壓供應必須均勻覆蓋整顆晶片,尤其在浮點運算單元和 Tensor Core 等電源密集熱點更需如此。
- 擺放(Placement):將數百萬個標準元件分配至平面規劃圖內的實體位置。全域擺放優化總導線長度並最小化壅塞熱點;詳細擺放則將這些位置合法化,將標準元件鎖定至定義好的網格行列並消除重疊。現代擺放器兼顧時序驅動與壅塞感知,在導線長度與可繞性之間取得平衡。上圖呈現的是設計中的元件密度分布。此步驟也會加入填充元件、Tap 元件與為 ECO 除錯預留的備用元件等基礎架構元件。
- 繞線(Routing):將所有已擺放元件連接至上方的金屬內連線堆疊,同時涵蓋訊號與電源。擺放繞線工具處理本地、半全域與全域繞線,以滿足電源輸送與時脈時序預算。在元件腳位密度過高、金屬堆疊無法容納的繞線壅塞區域,工具會適度分散標準元件、降低面積使用率。
- 時脈樹合成(Clock Tree Synthesis):建構從中央時脈源向每一顆電晶體分配時脈訊號的分配網路,確保同步運作。目標是最小化偏斜,即任何兩個功能單元之間的時脈到達時間差異。晶片中不同模組可能在不同時脈域運作以節省功耗,跨域傳遞訊號時需要時脈域交叉(clock domain crossing)機制。
- 可測試性設計(DFT):在實體實作中插入可測試性結構。掃描鏈與 DFT 存取墊片以長移位暫存器加入,讓測試設備可載入測試向量並取回結果。MBIST(記憶體內建自測試)為記憶體晶片加入晶片上的測試邏輯。ATPG(自動測試向量產生)軟體計算出能達到最大測試覆蓋率的最優輸入向量集。
實體設計是多輪優化迴路。每完成一個重大步驟,工具就執行一輪時序優化,包括在長走線或高扇出網路上插入緩衝器、調整閘尺寸(將標準元件替換為較大或較小的版本)、施加刻意的偏斜(調整時脈到達時間以助益關鍵路徑)、重映射邏輯(重構閘級拓撲),以及保持時間修復(加入延遲元件,防止資料過早到達)。工具在這些技術之間反覆迭代,以求最佳 PPA。
▉ 8. 簽核
就像 RTL 設計與驗證以 RTL Freeze 收尾,實體設計在鎖定 GDSII 前也需通過實體驗證(Physical Verification,PV),正式進入簽核。簽核的目的是證明設計在功能與可製造性兩方面,能在每種操作條件與每種功耗情境下實際正常運作。Synopsys 提供 IC Validator,Cadence 提供 Pegasus,Siemens 有 Calibre。這三套工具均在晶圓廠深度紮根,對無晶圓廠設計公司而言不可或缺。簽核前必須通過的主要檢查項目包括:
- 設計規則檢查(DRC):驗證晶圓廠的幾何約束是否均已遵守,包括最小線寬、形狀間距、強制阻擋區與圖案密度限制。先進製程節點的設計規則多達數千條,設計規則手冊頁數可超過 1,000 頁。
- 佈局對電路圖比對(LVS):證明實體佈局所實現的電路連接與設計意圖完全一致,無任何非預期的短路或斷路。從實體佈局提取網表後,與原始閘級網表進行比對,確保邏輯正確性。
- 電氣規則檢查(ERC):捕捉電源網路中的浮接節點、電源短路與其他電氣違規。ERC 還會檢查電流密度限制與 ESD(靜電放電)可靠性。
- 靜態時序分析(STA):驗證設計中每條時序路徑是否滿足建立與保持時間約束。Synopsys 的 PrimeTime 與 Cadence 的 Tempus 等工具可跨 PVT 角隅與 DVFS 曲線分析時序,即所謂的 MCMM(多角隅多模式)分析。
- 電源簽核:IR 壓降分析驗證電源分配網路能否在靜態(平均)與動態(切換)條件下,向每顆電晶體提供足夠電壓。導線電流也需通過電遷移(electromigration)限制的檢查,防止電子長期移動銅原子導致短路或斷路。Synopsys 的 RedHawk-SC 與 Cadence 的 Voltus 負責電源完整性驗證。
有時為了通過簽核,必須實施 ECO 流程。功能性 ECO 透過重新利用預先擺放的備用元件修復邏輯錯誤,只需更新最低金屬層的光罩。時序性 ECO 在 PrimeTime 的引導下調整或重映射元件以收斂時序,可能需要全套光罩更換。兩種類型在靈活性、成本與週轉時間之間各有取捨——其運作機制將在下文的「迭代版本」一節詳細說明。
統一設計流程
傳統上,晶片設計流程的每個階段各自獨立運作。RTL 團隊完成程式碼後交付給合成團隊,合成團隊產出網表後交付給擺放繞線團隊,後者再產出佈局並交付給簽核。每個工具獨立運作,一旦下游發現問題需要回頭修改佈局甚至 RTL,往往讓專案脫期數週。為解決這個問題,EDA 廠商已將實體設計流程統一,讓每個步驟不再依序而是同步考量。
Synopsys 的 Fusion Compiler 是這個問題的首個重要解答,以單一資料模型統一合成、擺放繞線與時序分析。Cadence 隨後推出 iSpatial,將 Innovus 的擺放與優化引擎直接嵌入 Genus 合成工具中。統一流程體現了「左移(Shift Left)」理念:在設計流程早期就引入簽核等級的分析,避免後期才出現的意外。
▉ 9. 流片
一旦所有簽核檢查通過,設計便以 GDSII 或 OASIS 格式匯出,這是描述每一層幾何形狀的業界標準格式。這份檔案送達晶圓廠,標誌著「流片」里程碑的完成——這個術語源自早年 GDSII 檔案以磁帶捲送出的往事。從此開始,首套光罩的製作啟動,OPC(光學鄰近效應校正) 演算法為光罩圖案加入 SRAF(次解析輔助特徵),以補償微影過程中的光學失真,接著進入光罩製作與晶圓製造。
▉ 10. 製造與封裝
從流片到取得第一批矽晶片,製造過程通常歷時 8 至 12 週。然而,購買 Hot Lot(優先晶圓穿梭)可以壓縮數週的週期時間,讓量產前驗證工程師更早取得晶片、提前開始除錯。
除錯工作開始前,矽晶片必須先封裝,以保護脆弱的晶粒,並將矽晶片表面細小的 I/O 凸點引出至可靠的可插拔封裝體上。在現代先進處理器上,異質整合(chiplets) 與**先進封裝** 在此發揮關鍵作用。每封裝多顆晶粒、3D 晶粒堆疊與 2.5D 矽中介層(例如 TSMC 的 CoWoS,即「晶圓上晶片再置於基板」技術),都是突破單一微影機最大曝光面積(26×33mm)限制、實現效能擴展的手段。
▉ 11. 矽晶片後驗證與量產啟動
Teradyne 與 Advantest 等廠商提供的自動測試設備(ATE),對每一顆出廠晶片施加先前由 ATPG 工具產生的數千個測試向量,逐一驗證。晶片內部的 JTAG 除錯介面,在矽晶片後除錯中提供直接存取,用以查找與預期行為不符的勘誤問題。初期量產啟動涉及多輪測試,每發現新的錯誤就更新原先在 FPGA 模擬器上開發的韌體,並實施對應的解決方案。量產執行時,這個步驟稱為最終測試(Final Test,FT),以回傳簡單通過或失敗結果的測試驗證功能。

來源:MPI Corp
為了存取封裝引出的每一條導線,工程師使用稱為探針卡(Probe Card) 的大型分接板,隔離每個訊號腳位,再接上示波器量測訊號完整性與強度,確認符合設計規格。
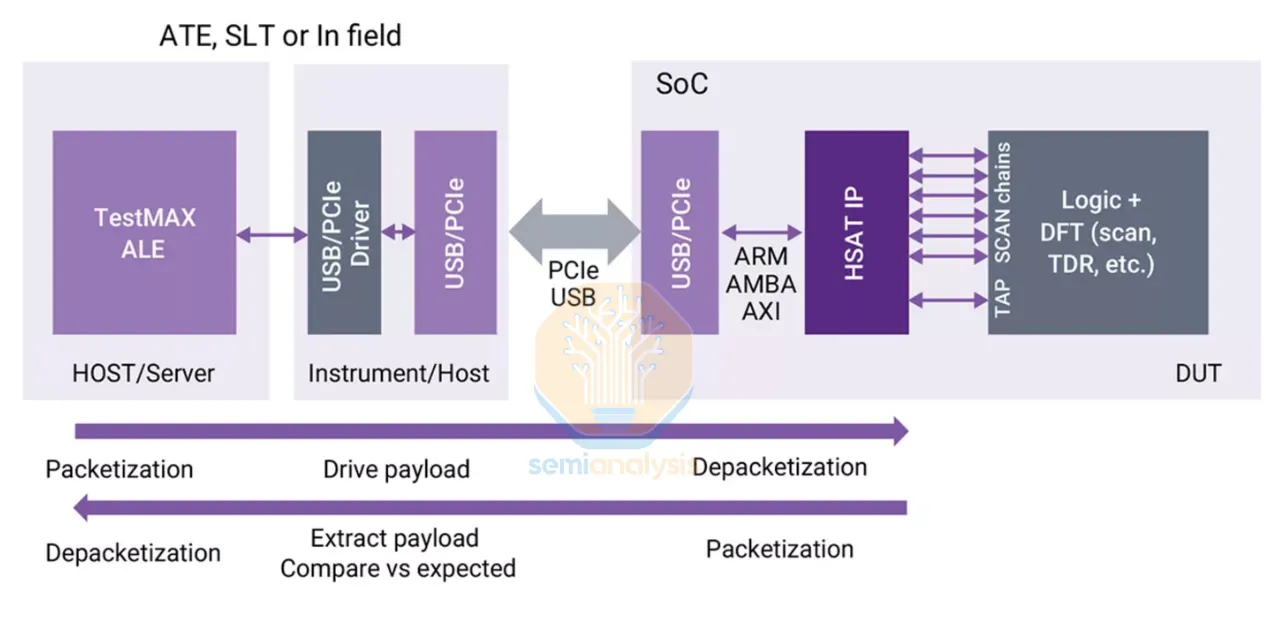
來源:Synopsys
EDA 廠商也在這個領域佔有一席之地。Synopsys 的 TestMAX 系列矽晶片後測試工具,提供從設計階段的 ATPG、良率診斷、DFT 結構與測試向量執行,到晶片測試管理與結果記錄的完整覆蓋。
老化測試

來源:NVIDIA
資格認證流程的下一個環節是熱可靠性測試——高溫運作壽命(High Temperature Operating Life,HTOL) 測試。這是一種加速老化測試,在超過一般操作溫度的條件下運作晶片,以篩除任何在額定操作環境與預期壽命內的熱循環中可能失效的瑕疵晶片。去除這批「嬰兒期死亡」晶片,大幅降低客戶收到早期失效產品的機率,符合可靠性「浴缸曲線」的預期模式。
測試時長依各設計的可靠性要求而定,一般在 72 至 168 小時之間。航太、汽車等可靠性關鍵應用可能長達 1,000 小時的壓力測試;成本敏感的低端消費性裝置則可能只從每批次產品中隨機抽取部分晶片進行延長測試。測試要求由 JEDEC 標準化,HTOL 遵循 JESD47,封裝可靠性的高濕度與溫度循環測試遵循 JESD22。
▉ 迭代版本
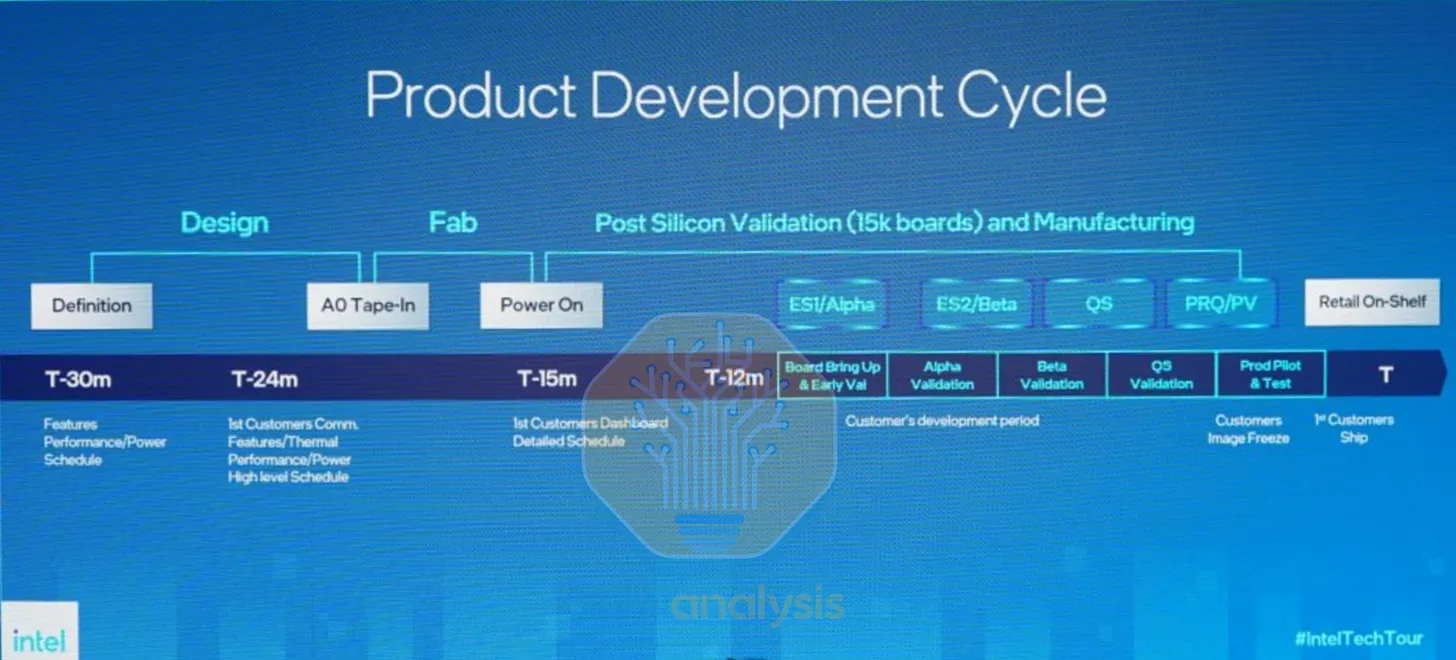
來源:Intel
從晶圓廠回廠的第一顆晶片稱為 A0 矽晶片。最理想的情況是 A0 直接達到效能、功耗與可靠性目標,無需任何調整即可進入量產。然而,有時第一顆晶片根本無法啟動,設計團隊必須找出根本缺陷。因此,多數設計團隊會預留額外的開發時間進行多次迭代版本(stepping)——更新晶片設計後,再次向晶圓廠送出新的 GDSII 檔案進行光罩製作與製造。
以上圖 Intel 的案例為例,實際量產前需要完成多輪工程樣品(Engineering Sample,ES)版本,以及最終通過驗證的資格認證樣品(Qualification Sample)。迭代版本有許多代號,例如 B1,乃至於長期延誤的 Intel Sapphire Rapids 所出現的 E5。以下是版本號代表意義的說明:
- 重大版本迭代(A0 到 B0):需要從設計工程(DE)到設計驗證(DV)再到實體驗證(PV)的完整流程,驗證工程師必須重新建立新的覆蓋率收斂,通常也需要完整更換光罩套組。
- 小幅版本迭代(A0 到 A1):通常是對金屬堆疊進行小幅光罩修改以修正錯誤,實作上一版本中已通過電路編輯驗證的修改。所需的設計與實體驗證規模較小。
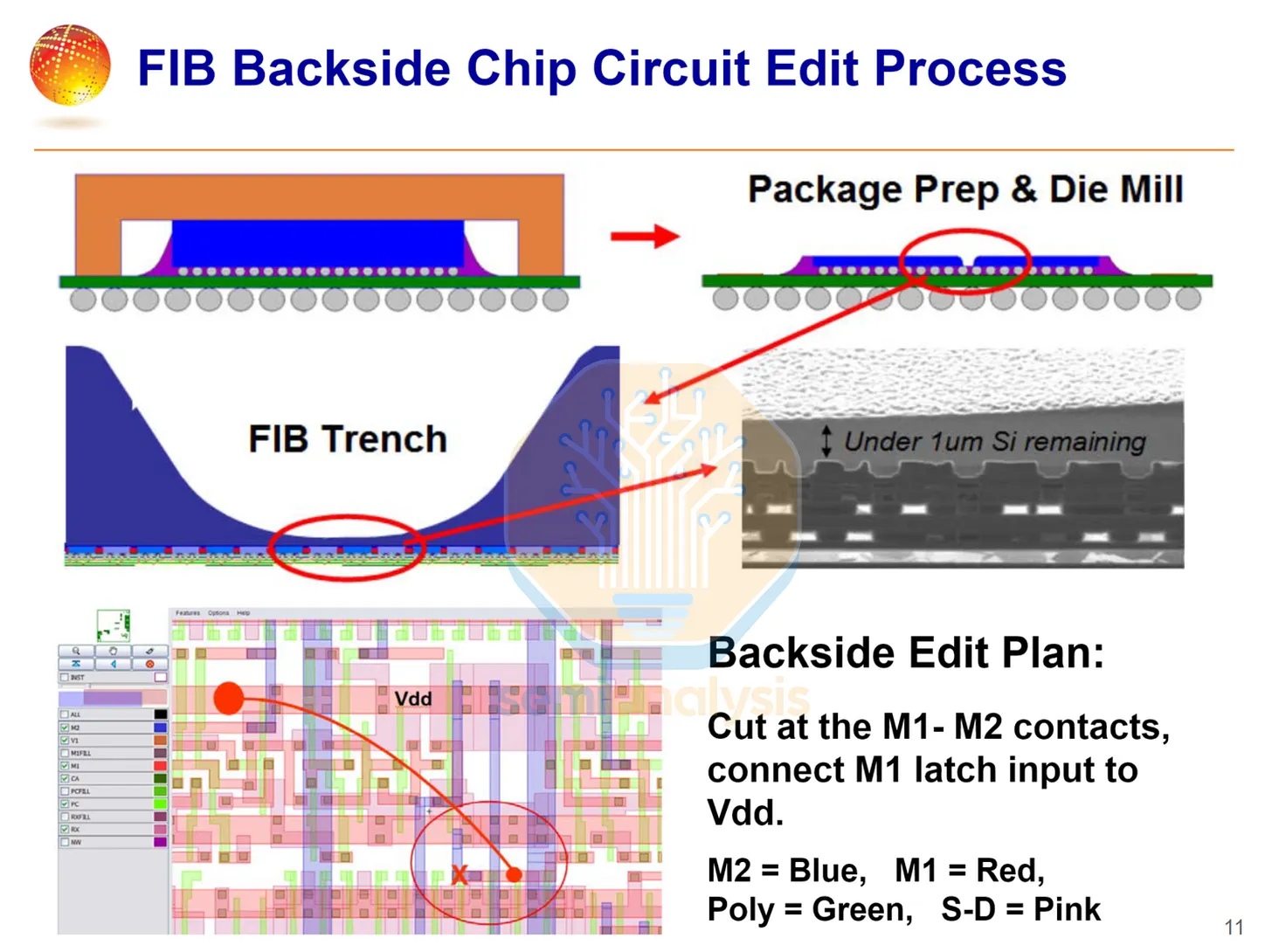
來源:GlobalFoundries
這種電路編輯使用先進的聚焦離子束(Focused Ion Beam,FIB) 工具進行,可在保持晶片完整功能的前提下,加入跳線或修改電晶體內連線圖案,以測試修復方案的有效性。設計可以透過預留緩衝元件或備用元件、保留更多繞線修改空間,來容納這個流程。由於此流程耗時,主要用於實體驗證下一版本計畫變更的有效性。
▉ 分級篩選
最後一步是速度分級篩選,將每顆晶片逐步在更高頻率下測試,通過最高時脈的晶片以高階產品出售。這種效能分布是製造過程中自然變異的結果。雖然此階段的晶片全部功能正常,但部分晶片可能需要比其他晶片略高的電壓,才能達到目標運行頻率。分級篩選也涵蓋良率收穫(yield harvesting):晶片中某些核心或子元件若有瑕疵,即被熔絲熔斷停用,以較低效能規格折扣出售。
分級篩選讓 Intel 得以打造其產品線——也就是著名的 Core i5、i7 與 i9 處理器品牌分類——而 NVIDIA GPU 因為良率收穫的緣故,幾乎從不以全部串流多處理器(SM)啟用的狀態出售。
▉ 12. 系統整合
通過驗證的晶片被置入參考電路板,與儲存、網路等裝置相連,完成驅動程式、BIOS 與作業系統支援的系統層級測試(SLT)。晶片接受各種壓力測試基準,並執行典型的軟體應用,確保終端用戶功能正常。
此外,這些電路板會搭配工程樣品矽晶片,分發給合作夥伴與開發者,以收集早期客戶回饋。這些參考驗證平台(Reference Validation Platform,RVP) 讓客戶提前介入開發週期,主要應用開發商可提早針對新晶片特性優化軟體,確保晶片上市當日即有軟體支援。
▉ 13. 量產
一旦量產就緒的迭代版本通過認證,良率達到令人滿意的水準,設計才終於可以開始擴大量產並交付客戶。然而工作並未就此結束。分析客戶退回的瑕疵矽晶片,有助於透過小幅修訂製造流程,消除設計中的最後盲點。設計公司持續與 TSMC 合作,參與持續改善流程(CIP),共同提升晶片良率。故障分析(FA)工程師使用 Synopsys Avalon 等工具,將特定缺陷映射至對應的電路圖,找出設計中受影響的邏輯閘與導線。
來源:Synopsys
▉ EDA 在晶圓廠的應用
除了無晶圓廠設計公司使用的工具,EDA 在晶圓廠內部也舉足輕重——晶圓廠藉此模擬與設計下一世代製程節點。此外,晶圓廠與無晶圓廠公司之間的緊密協作,以 DTCO 與 STCO 的形式,從晶圓廠製程中榨取更多 PPA。
技術計算機輔助設計(TCAD) 是物理模擬層,讓工程師在花費數千萬美元進行矽晶片實驗之前,先以軟體完整設計新的電晶體架構。主導工具套件是 Synopsys Sentaurus,由兩個核心引擎依序運作。Sentaurus Process 模擬每一道實際的製造步驟,包括離子佈植、氧化、薄膜沉積、電漿蝕刻、微影圖案化,並預測裝置的三維結構,精確到奈米尺度的摻雜分布。輸入一份製程配方,它就能模擬出輸出的裝置幾何形狀。
Sentaurus Device 則取用該三維結構,模擬其電氣行為,包括 I-V 曲線、電容、漏電電流與崩潰電壓。兩者合力,讓製程工程師能在複雜電晶體設計上不斷迭代,對環繞閘(Gate All Around)世代及其後的 CFET 與新型材料(如我們 IEDM 2025 報導中提及的釕)尤為關鍵。
Synopsys Mystic 再從模擬的電晶體中提取緊湊模型參數(業界標準的 SPICE 模型,如 BSIM-CMG)。裝置模擬結果被用來形成最早的 PDK 0.1,讓電路設計者在任何真實矽晶片存在之前的數月,就能提前開始設計。
深入到原子尺度的前沿,Synopsys QuantumATK 用於材料研究,在單個原子的尺度上進行模擬。它運用密度泛函理論(DFT) 與非平衡格林函數(NEGF) 方法,對量子傳輸與電子穿隧進行建模,服務於材料介面工程。這對精確控制電晶體門限電壓的功函數金屬化(Work Function Metallization)方案尤其有用。
設計回饋迴路
電晶體特性、IR 壓降與現有製程節點晶片的良率圖等矽晶片量測資料,直接回饋至晶圓廠下一代 PDK 的開發,以及設計團隊對未來節點更新的規劃。在節點的整個生命週期中,最佳已知方法(Best Known Methods,BKM) 不斷精煉,幫助客戶提升良率、降低晶圓廠的成本。這形成一個良性回饋迴路,客戶協助定義下一代晶圓廠製程。
DTCO:整合製程與設計
數十年來,晶片製造遵循嚴格的交接制度:製程工程師開發電晶體技術,完成表徵後再「翻牆交付」給晶片設計者,設計者只能接受給定的條件。設計製程共同優化(DTCO) 打破了這堵牆——從製程開發的第一天起,就以晶片層級的 PPA 指標評估製程選項。
DTCO 流程將整套工具鏈串接成一個回饋迴路:Sentaurus TCAD(裝置物理)→ Mystic(PDK)→ SiliconSmart/HSPICE(元件表徵)→ IC Compiler II/StarRC/PrimeTime(晶片層級 PPA 評估),結果再回饋給製程工程師。Apple、NVIDIA 與 AMD 等頂尖公司均設有專職的晶圓廠部門,與 TSMC 深度協作,打造專屬客製元件庫,PPA 最高可超越標準庫 15%。可繞性的改善直接轉化為更低延遲、更高效能、更低功耗,乃至因高壅塞繞線區面積使用率提升而帶來的面積縮減。
來源:TSMC
TSMC 的 FinFLEX 與 NanoFlex 等新型電晶體方案,讓 DTCO 幾乎成為充分發揮不同效能與漏電特性交替排列電晶體行的必要條件。Intel 18A 與 TSMC A16 的背面電源設計,在訊號與電源繞線上開拓了另一個維度,可能開啟繞越電晶體層兩側的全新標準元件繞線方案。
STCO:整合系統層級的共同優化
系統製程共同優化(STCO)將 DTCO 的概念再往上延伸一層——從晶片與製程的共同設計,擴展到系統與封裝的共同設計。它處理小晶片的分割決策、封裝技術選型、跨晶粒頻寬與延遲取捨、多晶粒散熱管理,以及整個封裝的電源完整性。隨著單一晶粒的縮放達到經濟與物理極限,STCO 正是業界持續實現世代效能躍升的方式。

來源:Intel
Intel 的 Ponte Vecchio GPU 是需要廣泛 STCO 的典型案例。它整合了橫跨五種不同製程節點製造的 47 顆主動晶粒,以 EMIB(嵌入式多晶粒互連橋接,2.5D 矽橋接)與 Foveros(Intel 的 3D 正面對正面晶粒堆疊)相互連接。然而,這顆晶片面臨多項設計挑戰,延誤長達數年,最終效能也遠低於最初目標。只要 STCO 應用得當,輔以健全的設計實踐,複雜設計如今已能按時、達標地完成,AMD 計畫在 2026 年底推出的 MI455X GPU 正是如此。
以下將討論晶片設計在真實世界中的實際面貌,以及工程師在設計複雜度不斷提升、設計週期持續壓縮的雙重壓力下所面臨的挑戰,並一覽 EDA 工具在模擬與模擬中實際運行的硬體。