CUDA 本體論
June 9, 2026 · 閱讀時間約 13 分鐘
 James Akl
James Akl  Kai-Yin Hung
Kai-Yin Hung 從 Compute Capability、編譯流程到執行期堆疊,一個觀念一個觀念解釋為何 nvidia-smi、nvcc 與 PyTorch 各自回報不同的 CUDA 版本號。

CUDA的五種變體
原文:CUDA ontology by James Akl(2025 年 11 月)本文改寫自原文,非逐字對照翻譯。
nvidia-smi 顯示 CUDA Version: 12.2,nvcc --version 顯示 12.1,torch.version.cuda 也顯示 12.1。哪個才是「真的」CUDA 版本?
全都是。但它們測量的是系統的不同面向。本文一個觀念一個觀念拆解清楚。
1. CUDA 這個詞有五種含義
CUDA 一詞至少有五種不同的含義:
- CUDA 作為計算架構: NVIDIA 設計的平行運算平台與程式設計模型。
- CUDA 作為指令集: NVIDIA 硬體支援的 GPU 指令集架構(ISA),以 compute capability 版本化(
compute_8.0、compute_9.0等)。 - CUDA 作為原始碼語言: 用於編寫 GPU 程式碼的 C/C++ 語言擴充(
__global__、__device__等)。 - CUDA Toolkit: 含
nvcc、函式庫、標頭檔與開發工具的開發套件。 - CUDA Runtime: 應用程式連結的 runtime 函式庫(
libcudart)。
當有人說「CUDA 版本」,可能指的是 toolkit 版本、runtime 版本、Driver API 版本或 compute capability。精確表達需要明確指定是哪一種。
kernel 在 CUDA 語境中有兩種完全不同的含義:
- OS kernel(作業系統核心): 在特權 kernel 空間執行的作業系統核心(Linux、Windows NT、macOS XNU)。
- CUDA kernel(GPU 函式): 以
__global__標記、在 GPU 上執行的 C++ 函式。
本文中,OS kernel 一律指作業系統核心,CUDA kernel 一律指 GPU 函式。
driver 同樣有兩種含義:
- NVIDIA GPU Driver: 管理 GPU 硬體的 OS kernel 空間 driver(Linux 上的
nvidia.ko,Windows 上的 OS kernel driver)。版本號如535.104.05。 - CUDA Driver API: 提供 GPU 功能直接存取的低階 C API(Linux 上的
libcuda.so,Windows 上的nvcuda.dll)。版本號如12.2、12.4。
NVIDIA GPU driver 套件同時包含 OS kernel 元件(nvidia.ko)與 libcuda 使用者空間函式庫——這是同一套件的兩個部分,但版本號不同。
2. GPU 的指令集:Compute Capability 與兩種程式碼格式
Compute capability(CC)是 GPU 硬體本身的屬性,定義它支援哪些指令集與硬體功能,與軟體版本無關:
- 格式:
X.Y(如8.0、8.9、9.0) - RTX 4090 的 CC 為
8.9,H100 的 CC 為9.0 - 透過
nvidia-smi --query-gpu=compute_cap --format=csv或cudaGetDeviceProperties()查詢
GPU 程式碼可編譯為兩種形式:
- SASS(Shader Assembly): 針對特定 CC 的 GPU 機器碼。編譯時就鎖定指令編碼,只能在相符的 CC 硬體上直接執行,無法跨 CC 移植。
- PTX(Parallel Thread Execution): NVIDIA 的虛擬指令集(ISA)。PTX 不與任何特定 GPU 架構綁定,由 GPU Driver 在執行期即時編譯(JIT)為目標 GPU 的 SASS。
這個差異是理解整個相容性體系的關鍵:針對 CC 8.0 編譯的 SASS 通常無法在 CC 8.6 或 9.0 硬體上執行,因為不同 CC 的指令編碼不同。PTX 不受此限制——GPU
Driver JIT 在執行期才將 PTX 降至目標 GPU 的原生指令,因此同一份 PTX 可以在更新的 GPU 上執行,不需要重新編譯。
SASS 的相容性限制:
- 同主版本內不保證相容: CC
8.0的 SASS 通常無法在 CC8.6硬體上執行,即使都是主版本 8.x。 - 不能在更舊的硬體上執行: CC
8.0的 SASS 無法在 CC7.5上執行(舊硬體缺少所需指令)。 - 不能跨主版本: CC
8.0的 SASS 無法在 CC9.0上執行(不同 ISA)。
3. 從原始碼到二進位:nvcc 編譯流程
nvcc 是 CUDA 的編譯器,負責將 .cu 原始碼編譯為包含 host 程式碼與 GPU 程式碼的二進位檔。
編譯流程:
.cu原始碼 包含 CUDA kernel 定義(__global__函式)與 host 程式碼。nvcc分離 device 程式碼(GPU)與 host 程式碼(CPU):- Device 程式碼編譯為 PTX 和/或針對指定 CC 的 SASS。
- Host 程式碼由 host 編譯器編譯(
g++或cl.exe)。
- 連結:目標檔與
libcudart(Runtime API)連結,產生包含 host 程式碼與嵌入 GPU 程式碼(PTX/SASS)的二進位檔。
-arch 與 -code 旗標:
-arch=compute_XY:設定虛擬架構(PTX 功能等級),決定編譯期可使用哪些 CUDA 功能。-code=sm_XY:針對特定 CC X.Y 產生 SASS(原生機器碼)。-code=compute_XY:在二進位檔中嵌入 CC X.Y 的 PTX,讓二進位檔能在執行期被 JIT 到更新的 GPU 架構。- 多個
-code目標可以逗號分隔。
建議: 務必同時指定 -arch 與 -code。若只指定 -arch 而未指定 -code,nvcc 隱式產生對應的 SASS 與 PTX,但行為不透明。
範例:
nvcc -arch=compute_80 -code=sm_80,sm_86,sm_89,compute_80 kernel.cu -o app這個指令產生四個輸出:CC 8.0(A100)、8.6(RTX 3090)、8.9(RTX 4090)的 SASS,以及 CC 8.0 的 PTX。執行時:
- A100(CC 8.0):直接載入 sm_80 SASS
- RTX 3090(CC 8.6):直接載入 sm_86 SASS
- H100(CC 9.0):無相符的 SASS,GPU Driver 將 CC 8.0 的 PTX JIT 編譯為 CC 9.0 的 SASS
編譯期 vs. 執行期需要哪些元件:
| 元件 | 編譯期 | 執行期 |
|---|---|---|
nvcc | 必要 | 不需要 |
CUDA 標頭檔(cuda.h 等) | 必要 | 不需要 |
libcudart(Runtime API) | 連結所需 | 執行所需 |
libcuda(Driver API) | 不直接使用 | 必要(系統級) |
GPU driver(nvidia.ko) | 不需要 | 必要 |
術語說明: 這裡的執行期(execution-time)指應用程式運行的時間點。這與 Runtime API(libcudart)不同——後者是執行期所需的特定 CUDA 函式庫名稱。
4. 執行期堆疊:五層元件如何串接
CUDA stack 實作 Separation of Concerns,將應用程式介面與硬體管理分為兩個獨立層次。
CUDA stack 橫跨 OS kernel 空間與使用者空間:
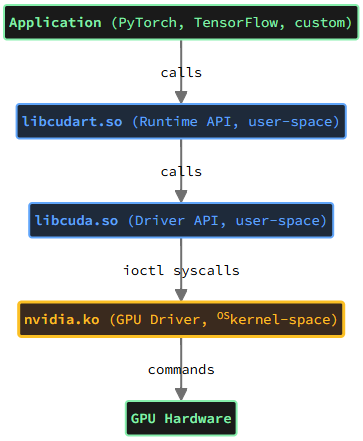
前端(應用程式層): libcudart.so + 應用程式程式碼,提供高階 Runtime API(cudaMalloc、cudaMemcpy 等),與應用程式一起打包或連結。
後端(系統層): libcuda.so + GPU driver(nvidia.ko),提供低階 Driver API 與硬體管理,系統級安裝。
這個分離的實際意義是部署獨立:GPU Driver 由 NVIDIA 透過 OS 套件管理,應用程式由開發者獨立發布,兩者不需要一起重裝或重編。升級 GPU Driver 不需要動 app;升級 app 也不需要動 GPU Driver 套件本身。但兩者之間仍有版本合約——如果 app 要求的 CUDA 版本比 GPU Driver 支援的更新,app 就會失敗(§6 詳述)。
元件定義
nvidia.ko(GPU Driver,OS kernel 空間):
- 執行在 OS kernel 空間,直接控制 GPU 硬體
- 職責:
- 透過 PCIe 與 GPU 晶片通訊
- 分配/釋放 VRAM,管理 CPU↔GPU 的 DMA 傳輸
- 維護 GPU command queue,排程工作負載
- 接收 GPU 完成工作後的 interrupt
- 管理 GPU 電源狀態
- 在 Linux 建立
/dev/nvidia*、/dev/nvidia-uvm等設備節點
- Windows 對應:
nvlddmkm.sys
libcuda.so / nvcuda.dll(CUDA Driver API,使用者空間):
- 執行在使用者空間,是
nvidia.ko的 userspace 代理人——程式不能直接進入 kernel,這個函式庫作為橋樑 - 職責:
- Context 管理:
cuCtxCreate/cuCtxDestroy(一個 context 對應 GPU 上的一個執行環境) - 記憶體 API:
cuMemAlloc/cuMemFree(轉換成 ioctl,讓nvidia.ko真正執行 VRAM 分配) - Module 載入:
cuModuleLoad(把 PTX/SASS 載入 GPU) - Kernel 啟動:
cuLaunchKernel(打包 grid/block 參數送給nvidia.ko排程) - Stream / Event 管理(非同步執行與同步點)
- Context 管理:
- 透過
ioctlsyscall(Linux)或DeviceIoControl(Windows)與nvidia.ko溝通 - 版本與 GPU Driver 版本掛鉤(GPU Driver
535.x提供 CUDA Driver API12.2) - 安裝位置:Linux
/usr/lib/x86_64-linux-gnu/libcuda.so,WindowsC:\Windows\System32\nvcuda.dll
libcudart.so / cudart64_*.dll(Runtime API,前端):
- 由 CUDA Toolkit 提供,或與應用程式一起打包(如 PyTorch)
- 高階 API:
cudaMalloc、cudaMemcpy、cudaLaunchKernel等,內部轉換為 Driver API 呼叫 - 可靜態連結(嵌入二進位檔)或動態連結
CUDA Toolkit:
- 開發套件,包含
nvcc、libcudart、標頭檔(cuda.h、cuda_runtime.h)、數學函式庫(cuBLAS、cuDNN、cuFFT)、效能分析工具(nvprof、nsight) - 版本獨立於 GPU driver
- 安裝路徑:Linux
/usr/local/cuda/,WindowsC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.x\ - NVIDIA 自 CUDA 10.2(2019 年)起已棄用 macOS 上的 CUDA 支援
執行流程:
- 應用程式呼叫
cudaMalloc、cudaLaunchKernel等(Runtime API) libcudart將呼叫轉換為 Driver API 呼叫(cuMemAlloc、cuLaunchKernel)libcuda.so透過ioctlsyscall 與nvidia.ko溝通- GPU Driver 排程 CUDA kernel 在 GPU 上執行
- GPU 執行 SASS 指令,處理資料,回傳結果
CUDA kernel「啟動」時,host 並不是把 C++ 原始碼送到 GPU。預先編譯的 SASS 或 PTX 已嵌入應用程式二進位檔(由 nvcc 在編譯期建立)。GPU
Driver 載入時,有 SASS 就直接載入,只有 PTX 就 JIT 編譯後再載入。
5. 四個版本號各自測量什麼
| 版本號 | 測量對象 | 查詢方式 |
|---|---|---|
| Compute Capability | GPU 硬體指令集版本 | nvidia-smi --query-gpu=compute_cap --format=csv |
| GPU Driver 版本 | nvidia.ko + libcuda.so 套件版本 | nvidia-smi(如 535.104.05) |
| CUDA Driver API 版本 | libcuda.so 提供的 API 版本 | nvidia-smi(顯示為 CUDA Version)或 cudaDriverGetVersion() |
| CUDA Toolkit 版本 | nvcc + libcudart + 標頭檔的版本 | nvcc --version |
| CUDA Runtime API 版本 | libcudart 提供的 API 版本 | cudaRuntimeGetVersion() 或 torch.version.cuda |
GPU Driver 版本(Linux 格式): R.M.P,如 535.104.05。每個 GPU Driver 版本決定支援的最高 CUDA Driver API 版本:
- Driver
535.x→ CUDA Driver API12.2 - Driver
550.x→ CUDA Driver API12.4
CUDA Toolkit 版本格式: X.Y.Z(如 12.1.0)。決定 nvcc 版本、libcudart 版本與可用 API 功能。
CUDA Runtime API 版本: 通常與 toolkit 版本相同(toolkit 12.1 提供 Runtime API 12.1 的 libcudart)。應用程式可能打包特定版本的
libcudart,這時 runtime 版本由打包的函式庫決定,而非系統 toolkit。
PyTorch 的兩個 CUDA 版本:
torch.version.cuda: 編譯期 toolkit 版本,即 PyTorch 構建時使用的 CUDA Toolkit 版本。- Runtime driver 版本: 執行時系統上可用的 CUDA Driver API 版本,由已安裝的 GPU driver 決定。
PyTorch 可能以 toolkit 12.1 編譯,但在支援 CUDA Driver API 12.4 的系統上執行,這樣的配置完全有效(12.4 ≥ 12.1)。
6. 相容性只走一個方向
先說結果:升級 GPU Driver 套件不會讓現有的應用程式壞掉;但如果應用程式要求的 CUDA 版本比現有 GPU Driver 支援的更新,唯一解法是升級 GPU Driver 套件。
CUDA Driver API 版本是 GPU Driver 套件的一部分(由 libcuda.so 提供),無法單獨升級。升級 GPU Driver 套件才會帶來更新的 CUDA Driver
API 版本。這就是 CUDA 相容性的核心規則——只支援一個方向。
Forward compatibility(向前相容) 的定義:新版 GPU Driver 能執行為舊版 CUDA Toolkit 編譯的應用程式。
- CUDA Driver API
12.4可以執行以 Runtime API12.1、12.2、12.3、12.4構建的應用程式。 - 你升級 GPU Driver 之後,舊程式不需要重新編譯,還是可以跑。
Backward compatibility(向後相容) 在 CUDA 不存在。舊版 GPU Driver 無法執行為較新 CUDA Toolkit 編譯的應用程式。
- CUDA Driver API
12.1無法執行需要 Runtime API12.4的應用程式。 - 這種情況沒有繞路,只能升級 GPU Driver 套件。
應用程式要成功執行,必須同時滿足兩個獨立條件:
條件一:API 版本相容性
Driver API version ≥ Runtime API versionDriver API 版本(由 libcuda.so 決定,取決於已安裝的 GPU driver)必須 ≥ Runtime API 版本(由 libcudart 決定,由應用程式打包或連結)。
條件二:GPU 程式碼可用性
Binary contains SASS for GPU's compute capability
OR
Binary contains PTX AND driver supports JIT compilation for GPU's architecture常見失敗模式:
cudaErrorInsufficientDriver:違反條件一(Driver API version < Runtime API version)cudaErrorNoKernelImageForDevice:違反條件二(GPU 無可用的 SASS 或 PTX)
Forward compatibility 在 CUDA 裡有兩個獨立的維度:
API 軸(GPU Driver 版本 vs. runtime 版本):新版 GPU Driver 支援較舊的 runtime,向前相容。這讓你可以安心升級 GPU Driver 而不影響現有應用程式。
GPU 程式碼軸(PTX vs. 較新 CC):針對 CC 8.0 編譯的 PTX 可被 GPU Driver JIT 編譯後在 CC 9.0
的硬體上執行。換了更新的 GPU 不一定要重新編譯應用程式,但首次啟動時需要付一次 JIT 成本。SASS 不具備此特性——SASS 在編譯時已鎖定指令編碼,無法被翻譯到不同 CC。
7. 讀懂 nvidia-smi、nvcc、PyTorch 的輸出
nvidia-smi
查詢 GPU driver,回報 driver 相關資訊。
回報: GPU driver 版本(535.104.05)、支援的最高 CUDA Driver API 版本(12.2)、GPU 型號、compute capability
不回報: CUDA Toolkit 版本、應用程式使用的 Runtime API 版本、nvcc 版本
輸出範例:
Driver Version: 535.104.05 CUDA Version: 12.2535.104.05:GPU driver 版本12.2:此 driver 支援的最高 CUDA Driver API 版本(需要 ≤ 12.2 的應用程式可在此系統上執行)
nvcc --version
回報已安裝的 CUDA Toolkit 版本(如 12.1.0)。
不回報: GPU driver 版本、目前使用的 Runtime API 版本
可能無法取得的情況:
- 未安裝 CUDA Toolkit(只安裝了 GPU Driver)
- 在 runtime-only 容器中執行(
-runtime映像不含nvcc) - 應用程式打包了
libcudart但未包含完整 toolkit
torch.version.cuda
回報 PyTorch 編譯時使用的 CUDA Toolkit 版本(如 "12.1")。這是構建期連結的版本,與系統安裝的 toolkit 無關。
torch.cuda.is_available()
回報布林值,表示 PyTorch 是否能存取支援 CUDA 的 GPU。回傳 False 表示版本不相容或缺少 GPU Driver。
cudaRuntimeGetVersion() 與 cudaDriverGetVersion()
在應用程式程式碼中以程式方式查詢:
int runtimeVersion, driverVersion;
cudaRuntimeGetVersion(&runtimeVersion); // 例如 12010(代表 12.1)
cudaDriverGetVersion(&driverVersion); // 例如 12040(代表 12.4)8. 七種失敗情境與解法
情境一:Runtime 版本 > Driver 版本
- GPU driver 支援 CUDA Driver API
12.1;應用程式以 Runtime API12.4構建。 - 失敗:
cudaErrorInsufficientDriver - 解法: 升級 GPU driver 至支援 CUDA Driver API ≥
12.4的版本。
情境二:編譯 compute capability > GPU compute capability
- 程式碼針對 CC
8.0(A100)編譯;在 CC7.5(RTX 2080 Ti)上執行。 - 失敗:
cudaErrorNoKernelImageForDevice - 解法: 針對 CC
7.5重新編譯(-arch=compute_75),或在二進位檔中加入 PTX。
情境三:缺少 PTX,無法 JIT
- 程式碼以
-code=sm_80編譯(只有 CC8.0的 SASS,無 PTX);在 CC9.0(H100)上執行。 - 失敗:
cudaErrorNoKernelImageForDevice - 解法: 重新編譯並加入 PTX:
-arch=compute_80 -code=sm_80,compute_80
情境四:PyTorch toolkit 版本 vs. GPU Driver 版本
| 配置 | 條件 | 結果 |
|---|---|---|
PyTorch 以 12.1 構建,GPU Driver 支援 CUDA Driver API 12.4 | 12.4 ≥ 12.1 | 成功 |
PyTorch 以 12.4 構建,GPU Driver 支援 CUDA Driver API 12.1 | 12.1 < 12.4 | cudaErrorInsufficientDriver |
失敗時的解法:升級 GPU driver。
情境五:多個 CUDA Toolkit,PATH 指向舊版
PATH指向/usr/local/cuda-12.1/bin,應用程式以 toolkit12.4編譯。- 結果:
nvcc --version回報12.1,應用程式 runtime 使用12.4,兩者不符。 - 注意:
nvcc --version回報的是PATH中的 toolkit,不是應用程式使用的版本。透過ldd ./app確認實際連結的libcudart版本。
情境六:Docker 容器用 runtime 映像但需要 nvcc
- 容器基於
nvidia/cuda:12.1-runtime,應用程式需要nvcc在執行期編譯 CUDA kernel。 - 失敗: 找不到
nvcc。 - 解法: 改用
nvidia/cuda:12.1-devel映像。
| 映像類型 | 包含 | 用途 |
|---|---|---|
-runtime | libcudart + 函式庫 | 執行預先編譯的 CUDA 應用程式 |
-devel | 完整 toolkit(nvcc、標頭檔) | 編譯 CUDA 程式碼 |
情境七:libcudart 靜態連結版本 > GPU Driver 支援的 CUDA Driver API 版本
- 靜態連結
libcudart_static.a(toolkit12.4);系統 GPU Driver 支援 CUDA Driver API12.1。 - 失敗:
12.1 < 12.4。 - 注意: 靜態連結將
libcudart嵌入二進位檔,版本在構建時決定。動態連結允許透過LD_LIBRARY_PATH在執行期選擇版本,靈活性較高。
9. 快速參考
元件關係總表
| 元件 | 提供者 | 位置(Linux / Windows) | 用途 | 版本類型 |
|---|---|---|---|---|
| OS kernel driver | NVIDIA GPU driver | nvidia.ko / nvlddmkm.sys | 管理 GPU 硬體 | Driver |
| Driver API 函式庫 | NVIDIA GPU driver | /usr/lib/libcuda.so / System32\nvcuda.dll | Driver API(低階) | Driver |
| Runtime 函式庫 | CUDA Toolkit | /usr/local/cuda/lib64 / CUDA\v12.x\bin | Runtime API(高階) | Toolkit |
nvcc | CUDA Toolkit | /usr/local/cuda/bin / CUDA\v12.x\bin | 編譯 CUDA kernel | Toolkit |
| 標頭檔 | CUDA Toolkit | /usr/local/cuda/include / CUDA\v12.x\include | 構建期 API 定義 | Toolkit |
| 數學函式庫 | CUDA Toolkit | /usr/local/cuda/lib64 / CUDA\v12.x\lib | GPU 運算函式庫 | Toolkit |
應用程式開發者
- 指定最低 CUDA Driver API 版本: 記錄應用程式所需的最低 CUDA Driver API 版本。
- 打包或指定 runtime 版本: 靜態連結
libcudart時確保 GPU Driver 相容性;動態連結時記錄所需的libcudart版本。 - 針對多種 compute capability 編譯: 使用
-arch與-code旗標;加入 PTX 以實現 forward compatibility。 - 在 runtime 檢查版本: 使用
cudaDriverGetVersion()與cudaRuntimeGetVersion()驗證相容性。
終端使用者
- 安裝適當的 GPU driver: GPU driver 支援的 CUDA Driver API 版本必須 ≥ 應用程式的 runtime 需求。
- Runtime 不需要安裝 Toolkit: 只需要
libcudart(通常已打包)與 GPU driver。 - 確認相容性:
nvidia-smi顯示 GPU Driver 版本與支援的最高 CUDA Driver API 版本。
PyTorch / TensorFlow 使用者
torch.version.cuda是構建期版本,不需要與系統 toolkit 相符。- 系統 GPU driver 必須支援 CUDA Driver API ≥
torch.version.cuda。 - 例如:
torch.version.cuda = "12.1",nvidia-smi顯示CUDA Version: 12.4→ 有效(12.4 ≥ 12.1)。 - TensorFlow 遵循相同的相容性模型,查閱 release notes 以了解構建 toolkit 版本。
Docker / 容器使用者
-runtime映像: 包含libcudart與函式庫,不含nvcc。-devel映像: 包含完整 toolkit,編譯 CUDA 程式碼所需。- NVIDIA Container Toolkit: 確保容器能存取 host GPU。Host 上的 GPU driver 版本決定容器可用的最高 CUDA Driver API 版本。
設計哲學
CUDA 的設計目標是讓 GPU 硬體的多樣性對應用程式不可見。兩個機制互補實現這件事:PTX 讓一份 binary 可以跨 GPU 世代執行(GPU Driver 在 runtime 看到新硬體就 JIT);向前相容讓一份 binary 可以跨 GPU Driver 版本執行(新版 Driver 相容舊版 runtime 請求)。代價是你必須理解三層各自的版本——GPU 硬體(Compute Capability)、GPU Driver 套件(CUDA Driver API 版本)、應用程式(Runtime API 版本)——因為任何一層脫節,執行就失敗,且錯誤訊息不會告訴你是哪一層。